象甲——使用MFC多线程编程加速运算
本篇接自上一篇“基于MFC的象棋AI程序——象甲”。
上一篇中我们使用一定的局面评估知识和ab搜索算法已经为象棋AI取得了不错的成绩,如何进一步提升呢?除了改进启发式知识和使用更先进的算法,使用多线程技术充分利用电脑的多核性能加速计算也十分有效。
首先看一下单线程版本的象甲运行时的CPU使用率,后面可以做一个比较。
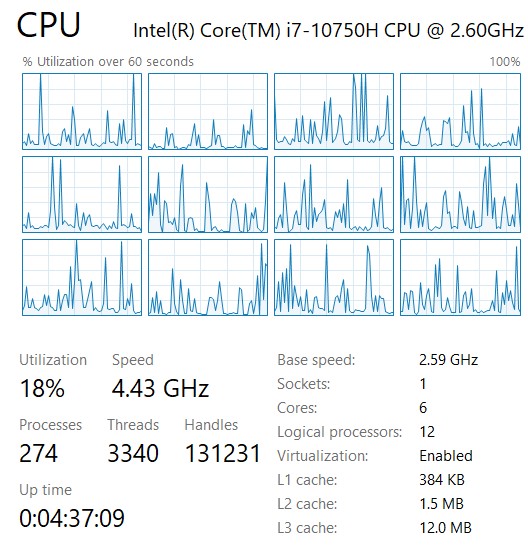
我是6核12线程的CPU,运行单线程时使用率仅仅20%不到,可见还有大量的算力没有用到。
在之前版本的代码之上进行修改,设想的方法是在外层初次调用的shieldAlphaBeta()函数中为下一层的每个alphaBeta()函数创建一个独立的线程从而做到并发计算。每个线程得出各自的计算结果后,比较取分数最高的即可。
MFC中创建工作线程的函数是AfxBeginThread(ThreadFunc, lPrarm);,参数ThreadFunc为函数名,lPrarm为函数参数。
为了把所需的一系列参数传入线程函数,构造一个参数结构体。
//AlphaBeta线程函数所需参数
struct threadFuncPara {
int ctrl_col;
int board[9][10];
int searchDepth;
int currentDepth;
int i;
int j;
int n0;
int n1;
};
下面编写线程函数,线程函数最主要的功能是调用alphaBeta()函数和更新Alpha值,由于多线程并行计算,使用共同的Alpha值进行更新,因此将Alpha定义为全局变量可供不同线程共同访问,取分数更高的Alpha进行更新。在每次读取和更新时使用临界区线程锁保护数据读写,防止读写发生冲突。临界区对象使用CCriticalSection类定义,上锁与解锁也十分简单,分别调用成员函数Lock()与Unlock()即可。
线程的数量应得到限制,过多的线程会占用超量系统资源引发崩溃,同时也会增大线程间切换的上下文开销,得不偿失。在本例中限制线程数量还有一个最重要的好处,减少每次同时运行的线程数量可以使之后运行的线程读取到更新后的Alpha值,加快Alpha值的更新速度将显著增加剪枝率,从而减少总体上检索的节点数量,加快计算。因此应该选取合适的线程数量,在并行量和总体计算量间达到平衡,从而使所需时间缩减到最少。
线程数量使用信号量CSemaphore类来控制。创建信号量对象CSemaphore semaphoreWrite(threadLimit, threadLimit);。参数threadLimit为信号量大小。发出与释放信号量分别采用方法WaitForSingleObject(semaphoreWrite.m_hObject, INFINITE);和ReleaseSemaphore(semaphoreWrite.m_hObject, 1, NULL);。
最终的线程函数和相关对象定义如下。
mark Alpha; //多线程共享alpha输出
int threadLimit = 5; //工作线程数量限制
CCriticalSection critical_section; //临界区线程锁
CSemaphore semaphoreWrite(threadLimit, threadLimit); //信号量
//使用信号量的好处:1.控制线程数量,防止进程崩溃;2.减小信号量,可使Alpha快速更新,从而减少所需检索的节点数量,因此调整信号量以获得最优效率
UINT ThreadFunc(LPVOID lpParam)
{
WaitForSingleObject(semaphoreWrite.m_hObject, INFINITE); //增加信号量
mark result;
mark alpha;
critical_section.Lock(); //使用线程锁保证读写不冲突
alpha = Alpha;
critical_section.Unlock();
mark beta;
beta.score = INT_MAX; //beta设为最大值
threadFuncPara* tfParamNext = (threadFuncPara*)lpParam;
int c = 0; //线程内节点计数
result.score = AlphaBeta(tfParamNext->ctrl_col, tfParamNext->board, tfParamNext->searchDepth, tfParamNext->currentDepth, alpha, beta, &c).score;
result.cx = tfParamNext->i;
result.cy = tfParamNext->j;
result.tx = tfParamNext->n0;
result.ty = tfParamNext->n1;
critical_section.Lock();
if (result.score > Alpha.score)
Alpha = result;
count += c;
critical_section.Unlock();
delete tfParamNext; //释放tf参数
ReleaseSemaphore(semaphoreWrite.m_hObject, 1, NULL); //释放信号量
return 0;
}
工作线程函数搞定之后,只需要修改一下原有的外层函数调用,在其中创建线程,并等待所有创建的线程执行完毕后返回。等待多线程执行使用函数WaitForMultipleObjects(threadNum, threadList, TRUE, WSA_INFINITE);。其中参数分别为线程数量,线程句柄列表,是否等待所有线程,等待时间。
修改后的外层函数如下。
mark CxiangjiaDlg::threadShieldAlphaBeta(const int ctrl_col, const int board[9][10], const int searchDepth, mark shield)
//使用多线程且带有屏蔽走法的外层统一入口,输入参数:控制颜色,棋盘,搜索深度,屏蔽走法
{
//int currentDepth = 1; //初始当前深度为1
int oppo_col = (ctrl_col == red) ? black : red;
int i, j, n;
int moverableList[20][2];
int num = 0;
int fancyBoard[9][10];
threadFuncPara* tfParamNext; //tf参数
CWinThread* pThread;
int threadNum = 0; //正在运行的工作线程数量
HANDLE threadList[120]; //创建的线程数组,用于集体等待完成
Alpha.score = INT_MIN; //初始化全局Alpha,设为最小值
count += 1; //初始化计数
for (i = 0; i < 9; i++)
{
for (j = 0; j < 10; j++)
{
if (!isSameColor(ctrl_col, board[i][j])) //只能操控本方棋子
continue;
moverablePosition(board[i][j], i, j, board, moverableList, &num); //更新棋子可走位置列表
for (n = 0; n < num; n++) //遍历可走位置
{
//屏蔽判断
if (i == shield.cx && j == shield.cy && moverableList[n][0] == shield.tx && moverableList[n][1] == shield.ty)
continue;
//快速胜利判断
if (board[moverableList[n][0]][moverableList[n][1]] == rjiang || board[moverableList[n][0]][moverableList[n][1]] == bjiang)
{
mark result;
result.score = 10000 - 100;
result.cx = i;
result.cy = j;
result.tx = moverableList[n][0];
result.ty = moverableList[n][1];
critical_section.Lock();
if (result.score > Alpha.score)
Alpha = result;
critical_section.Unlock();
}
else
{
copyBoard(board, fancyBoard);
//接下来全部使用fancyBoard
move(fancyBoard[i][j], i, j, moverableList[n][0], moverableList[n][1], fancyBoard);
//注意内层不需要shield
tfParamNext = new threadFuncPara;
tfParamNext->ctrl_col = oppo_col;
copyBoard(fancyBoard, tfParamNext->board);
tfParamNext->searchDepth = searchDepth;
tfParamNext->currentDepth = 2;
tfParamNext->i = i;
tfParamNext->j = j;
tfParamNext->n0 = moverableList[n][0];
tfParamNext->n1 = moverableList[n][1];
//启动线程
pThread = AfxBeginThread(ThreadFunc, tfParamNext);
//将线程句柄加入列表
threadList[threadNum++] = pThread->m_hThread;
}
}
}
}
//等待所有线程执行完毕
WaitForMultipleObjects(threadNum, threadList, TRUE, WSA_INFINITE);
return Alpha;
}
经过测试,我选取的最优信号量为5,使用多线程运行的象甲CPU使用率达到了75%左右,并且在时间消耗可接受的范围内将搜索层数提升了1层,进一步增强了AI的实力。
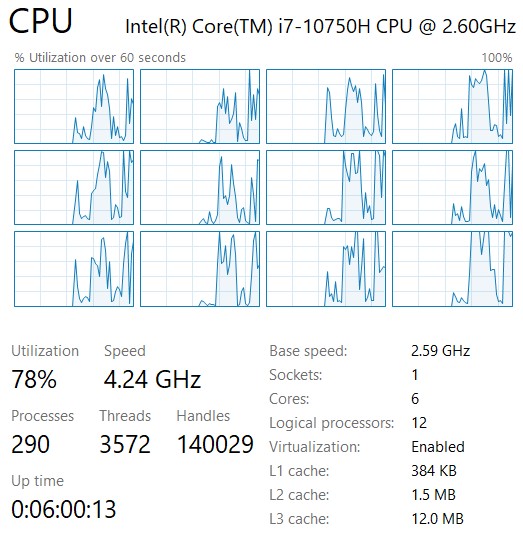
补充:在一些配置较低的机器上,以上这种肆意创建线程的方法可能难以起到很好的效果,甚至由于线程数量过多造成程序错误崩溃(虽然使用了信号量,但大量线程仍然被创建了)。一个简单的解决方法是使用类似于线程池的方法,首先装载整个任务队列,然后创建有限数量的线程,由这些线程抢占式执行任务,直到任务队列为空。
UINT ThreadFunc(LPVOID lpParam)
//线程函数,不断获取任务参数直到任务列表为空
{
threadFuncPara* threadParam = (threadFuncPara*)lpParam;
taskFuncPara* taskParam;
while (1)
{
threadParam->ccs1->Lock();
if (*(threadParam->leftTaskNum) == 0)
break;
taskParam = *(threadParam->taskList + --(*(threadParam->leftTaskNum)));
threadParam->ccs1->Unlock();
taskFunc(taskParam, threadParam->ccs2);
}
threadParam->ccs1->Unlock();
return 0;
}
mark CxiangjiaDlg::threadShieldAlphaBeta(const int ctrl_col, const int board[9][10], const int searchDepth, mark shield)
//使用多线程且带有屏蔽走法的外层统一入口,输入参数:控制颜色,棋盘,搜索深度,屏蔽走法
{
int oppo_col = (ctrl_col == red) ? black : red;
int i, j, n;
int moverableList[20][2];
int num = 0;
int fancyBoard[9][10];
mark result;
taskFuncPara* tfParamNext; //任务函数参数
taskFuncPara* taskParmList[128]; //任务参数队列,交给线程执行
int taskParmNum = 0; //任务数量
threadFuncPara threadParam; //线程函数参数
HANDLE* threadList = new HANDLE[threadLimit]; //线程列表,线程池
CWinThread* pThread;
Alpha[0].score = INT_MIN; //初始化全局Alpha,设为最小值
count += 1; //初始化计数
AlphaListNum = 0; //初始化AlphaList计数
CCriticalSection critical_section1; //临界区线程锁1,用于管理任务接收
CCriticalSection critical_section2; //临界区线程锁2,用于更新Alpha
//CSemaphore semaphoreWrite(threadLimit, threadLimit); //信号量
//使用信号量的好处:1.控制线程数量,防止进程崩溃;2.减小信号量,可使Alpha快速更新,从而减少所需检索的节点数量,因此调整信号量以获得最优效率
for (i = 0; i < 9; i++)
{
for (j = 0; j < 10; j++)
{
if (!isSameColor(ctrl_col, board[i][j])) //只能操控本方棋子
continue;
moverablePosition(board[i][j], i, j, board, moverableList, &num); //更新棋子可走位置列表
for (n = 0; n < num; n++) //遍历可走位置
{
//屏蔽判断
if (i == shield.cx && j == shield.cy && moverableList[n][0] == shield.tx && moverableList[n][1] == shield.ty)
continue;
//快速胜利判断
if (board[moverableList[n][0]][moverableList[n][1]] == rjiang || board[moverableList[n][0]][moverableList[n][1]] == bjiang)
{
result.score = 10000 - 100;
result.cx = i;
result.cy = j;
result.tx = moverableList[n][0];
result.ty = moverableList[n][1];
updateAlphaList(result);
}
else
{
copyBoard(board, fancyBoard);
//接下来全部使用fancyBoard
move(fancyBoard[i][j], i, j, moverableList[n][0], moverableList[n][1], fancyBoard);
//注意内层不需要shield
tfParamNext = new taskFuncPara;
tfParamNext->ctrl_col = oppo_col;
copyBoard(fancyBoard, tfParamNext->board);
tfParamNext->searchDepth = searchDepth;
tfParamNext->currentDepth = 2;
tfParamNext->i = i;
tfParamNext->j = j;
tfParamNext->n0 = moverableList[n][0];
tfParamNext->n1 = moverableList[n][1];
//将任务参数加入列表
taskParmList[taskParmNum++] = tfParamNext;
}
}
}
}
threadParam.leftTaskNum = &taskParmNum;
threadParam.taskList = taskParmList;
threadParam.ccs1 = &critical_section1;
threadParam.ccs2 = &critical_section2;
//启动线程池,线程数量由用户设定
for (i = 0; i < threadLimit; i++)
{
pThread = AfxBeginThread(ThreadFunc, &threadParam);
threadList[i] = pThread->m_hThread;
}
//等待所有工作线程执行完成
WaitForMultipleObjects(threadLimit, threadList, TRUE, 60 * 1000); //等待最长一分钟,防止有线程异常导致程序无响应,无限为WSA_INFINITE
result = Alpha[rand() % AlphaListNum];
//清除残留的线程,危险方法,不推荐
for (i = 0; i < threadLimit; i++)
{
if (TerminateThread(threadList[i], -1) && !disableWarning)
{
AfxMessageBox(_T("Certain thread was terminated unexpectedly."));
}
}
delete []threadList;
return result; //走子随机化rand() % AlphaListNum
}