基于MFC的象棋AI程序——象甲
编译环境:visual studio 2019 Enterprise
寒假里花费不短的时间开发了一款中国象棋ai程序,开发这个程序完全是基于兴趣(自己的棋艺很差,想让电脑实现一些我做不到的事情)。
话不多说,象甲的核心游戏引擎和AI引擎全部采用C/C++语言编写,其中AI引擎采用了alpha-beta算法,图像界面方面一开始想使用开发快速的python,但考虑到语言的一致性和跨语言调用不便等问题,最终还是选择了复杂一点的MFC编程(感谢鸡啄米大佬引领我一路学习了MFC)。
为了与我的开发过程一致,这里也先从游戏引擎开始讲起。抛开界面的实现不谈,要想实现中国象棋,首先要完成这么几个方面的需求:棋子和棋局的表示、棋子的移动规则、棋子的移动和胜利判断等。
由于象棋中涉及多种棋子,每一种棋子(例如车、马、炮)都有自己的移动和攻击方式,而所有棋子都有一定的共性(如可以移动、攻击、有所属的颜色等),因此我一开始采用了多态的思想来开发。
首先编写棋子父类,每一颗棋子都拥有一些共有的属性如颜色、种类、坐标、下一步可以移动的位置等,在AI评估阶段还会涉及这颗棋子的子力价值,这些都是棋子父类的成员变量。而棋子间不同的是棋子的移动规则,需要子类的继承和重写。基于此,编写棋子父类。
//棋子颜色和种类
enum class colors { none, red, black };
enum class types { none, che_, ma_, pao_, bing_, xiang_, shi_, jiang_ };
//坐标,右下角为(0,0)
typedef struct position {
int x = -1;
int y = -1;
}position;
//棋子父类
class chessman
{
public:
colors colour = colors::none;
types species = types::none;
position pos; //当前坐标
int imageNo = -1;
position next_moverable[20]; //下一步可走位置列表
int num = 0; //下一步可走位置数量
int value = 0; //子力价值
void moverable_position(chessman* board[9][10]);
int move(position target, chessman* operate_board[9][10]);
};
接着是棋局表示,这个很简单,一个9行10列的二维数组便可以搞定,数组中保存每个位置的棋子。当然还需要一个变量来代表空的位置。
extern chessman reset; extern chessman* checkerboard[9][10];
根据所有棋子各自的特性,编写它们各自的子类,生成不同的构造函数。
//车
class che :virtual public chessman
{
public:
che(colors c)
{
species = types::che_;
colour = c;
if (colour == colors::black)
{
imageNo = 1;
}
else
{
imageNo = 8;
}
value = 8;
}
};
//马
class ma :virtual public chessman
{
public:
ma(colors c)
{
species = types::ma_;
colour = c;
if (colour == colors::black)
{
imageNo = 2;
}
else
{
imageNo = 9;
}
value = 4;
}
};
//炮
class pao :virtual public chessman
{
public:
pao(colors c)
{
species = types::pao_;
colour = c;
if (colour == colors::black)
{
imageNo = 3;
}
else
{
imageNo = 10;
}
value = 4;
}
};
//兵
class bing :virtual public chessman
{
public:
bing(colors c)
{
species = types::bing_;
colour = c;
if (colour == colors::black)
{
imageNo = 6;
}
else
{
imageNo = 13;
}
value = 1;
}
};
//象
class xiang :virtual public chessman
{
public:
xiang(colors c)
{
species = types::xiang_;
colour = c;
if (colour == colors::black)
{
imageNo = 5;
}
else
{
imageNo = 12;
}
value = 2;
}
};
//士
class shi :virtual public chessman
{
public:
shi(colors c)
{
species = types::shi_;
colour = c;
if (colour == colors::black)
{
imageNo = 4;
}
else
{
imageNo = 11;
}
value = 2;
}
};
//将
class jiang :virtual public chessman
{
public:
jiang(colors c)
{
species = types::jiang_;
colour = c;
if (colour == colors::black)
{
imageNo = 0;
}
else
{
imageNo = 7;
}
value = 1000;
}
};
到这里,棋子和棋局的基本框架已经出来了。
先暂停一下,我使用上面的继承多态的方法实现了全部的象棋功能和AI引擎后,发现在实际AI运算过程中由于涉及到大量的对象操作和内存的拷贝,不仅速度缓慢,而且编写过程复杂,复制对象时涉及到的拷贝构造函数对于我这么一个半瓶水的C++程序员来说伤透了脑筋。因此最后,我还是选择忍痛放弃已经形成的框架,转而使用基本的C语言思想通过普通二维数组来表示棋局,不仅编写简单而且运算速度大大加快。鉴于此,我不再给出面向对象部分的代码,下面的例子直接以最终的成果展现。
下一步是编写棋子的移动规则。由于编写的规则既要能够约束用户的落子,保证落子合法,又要提供给AI引擎棋子可到达的位置。因此可以基于棋盘生成每一颗棋子下一步可以到达的所有位置,包括移动和吃子。这样只要判断用户的落点是否在可移动位置列表中即可实现规则约束。
例如,车可以横线或纵向行进,但会被其他子挡住,被挡住时还要判断挡住的是对方的子(可以吃)还是自己的子,炮不仅可以行进还可以隔子攻击等等。我不再一一陈述所有子的具体判断方式,实现的想法并不困难,由于代码量大,这里只给出车的代码,想查看全部代码的同学直接去下载工程源文件。
void moverablePosition(const int chess, const int x, const int y, const int board[9][10], int moverableList[20][2], int* num)
// 输入变量:棋子类型,棋子x坐标,棋子y坐标,棋盘,输出坐标列表,输出可走位置数量
{
int i;
(*num) = 0;
switch (chess)
{
case rche:
case bche:
for (i = x + 1; i <= 8; i++) //搜索棋子左侧可走位置
{
if (board[i][y] == none)
{
moverableList[(*num)][0] = i;
moverableList[(*num)][1] = y;
(*num)++;
}
else if (!isSameColor(chess, board[i][y])) //判断能不能吃
{
moverableList[(*num)][0] = i;
moverableList[(*num)][1] = y;
(*num)++;
break;
}
else
{
break;
}
}
for (i = x - 1; i >= 0; i--) //搜索棋子右侧可走位置
{
if (board[i][y] == none)
{
moverableList[(*num)][0] = i;
moverableList[(*num)][1] = y;
(*num)++;
}
else if (!isSameColor(chess, board[i][y])) //判断能不能吃
{
moverableList[(*num)][0] = i;
moverableList[(*num)][1] = y;
(*num)++;
break;
}
else
{
break;
}
}
for (i = y + 1; i <= 9; i++) //搜索棋子上方可走位置
{
if (board[x][i] == none)
{
moverableList[(*num)][0] = x;
moverableList[(*num)][1] = i;
(*num)++;
}
else if (!isSameColor(chess, board[x][i])) //判断能不能吃
{
moverableList[(*num)][0] = x;
moverableList[(*num)][1] = i;
(*num)++;
break;
}
else
{
break;
}
}
for (i = y - 1; i >= 0; i--) //搜索棋子下方可走位置
{
if (board[x][i] == none)
{
moverableList[(*num)][0] = x;
moverableList[(*num)][1] = i;
(*num)++;
}
else if (!isSameColor(chess, board[x][i])) //判断能不能吃
{
moverableList[(*num)][0] = x;
moverableList[(*num)][1] = i;
(*num)++;
break;
}
else
{
break;
}
}
break;
......
还需要一些其他的功能函数比如移动。在抛弃了多态的想法后移动函数十分简单,修改一下棋盘数组即可,当然如果是用户进行移动操作还要先判断用户的移动是否合法,判断方法只要利用刚刚描述的走子规则即可。
int move(const int chess, const int ox, const int oy, const int tx, int const ty, int board[9][10], int valid)
//移动一颗棋子,输入参数:棋子种类,棋子原x坐标,棋子原y坐标,棋子目标x坐标,棋子目标y坐标,棋盘,是否验证合法性(默认为0)
{
if (valid)
{
int i;
int moverableList[20][2] = { 0 };
int num = 0;
moverablePosition(chess, ox, oy, board, moverableList, &num); //移动需合法
for (i = 0; i < num; i++)
{
if (tx == moverableList[i][0] && ty == moverableList[i][1])
{
board[tx][ty] = chess;
board[ox][oy] = none;
return 1;
}
}
return 0;
}
else
{
board[tx][ty] = chess;
board[ox][oy] = none;
return 1;
}
}
游戏胜利的判断。如果棋盘上有任一个将被吃,则游戏结束并且判断胜利的一方。
int isGameOver(const int board[9][10])
{
int i, j;
int vic_r = red, vic_b = black;
for (i = 3; i <= 5; i++)
{
for (j = 0; j <= 9; j++)
{
if (j == 3)
{
j = 6;
continue;
}
if (board[i][j] == rjiang)
{
vic_b = none;
}
if (board[i][j] == bjiang)
{
vic_r = none;
}
}
}
return vic_r ? red : (vic_b ? black : none);
}
游戏的初始化。摆放初始化棋盘。
int iniboard[9][10] = {
{rche, none, none, rbing, none, none, bbing, none, none, bche},
{rma, none, rpao, none, none, none, none, bpao, none, bma},
{rxiang, none, none, rbing, none, none, bbing, none, none, bxiang},
{rshi, none, none, none, none, none, none, none, none, bshi},
{rjiang, none, none, rbing, none, none, bbing, none, none, bjiang},
{rshi, none, none, none, none, none, none, none, none, bshi},
{rxiang, none, none, rbing, none, none, bbing, none, none, bxiang},
{rma, none, rpao, none, none, none, none, bpao, none, bma},
{rche, none, none, rbing, none, none, bbing, none, none, bche}};
int checkerboard[9][10];
void initialize()
{
int i, j;
for (i = 0; i <= 8; i++)
{
for (j = 0; j <= 9; j++)
{
checkerboard[i][j] = iniboard[i][j];
}
}
}
游戏过程中还要频繁判断两个棋子的颜色是否相同。
int isSameColor(const int a, const int b)
//a是一个非空棋子,b是任意棋子,判断颜色是否相同
{
if (a >= 1 && a <= 7)
{
return (b >= 1 && b <= 7);
}
else
{
return (b >= 8 && b <= 14);
}
}
全部编写好后,整个象棋引擎所需要的全部功能就完成了,接下来可以放心的开始其他部分的编写。
下面开始讲述GUI图形界面部分,我使用了MFC框架。
由于MFC中涉及的知识点众多,我这里不可能一一给大家讲解,因此我还是只给出大致的涉及思路和框架,至于具体的实现细节的理解,欢迎大家参考鸡啄米大神的MFC教程,学习MFC编程的基本知识。
先大致梳理一下我们的象棋程序希望实现的功能。首先先确定两个模式,一个是玩家之间自己玩的自由模式,还有一个就是AI对战模式。在AI对战模式下,还可以提供选择游戏的难度,这些有关模式选择的内容可以设计一个对话框统一实现。
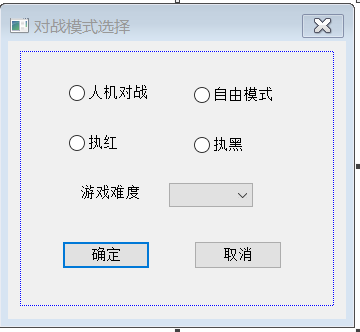
还有一些必要的功能比如悔棋、游戏过程中翻转棋盘显示、切换模式等,都需要一一实现。此外,我还添加了棋盘编辑功能,用户可以在棋盘上自由添加或删除棋子,来实现一些打残棋或其他想自由尝试的下法。
上面这些功能统一整合到右键菜单之中。
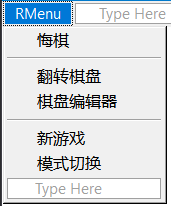
在给出每个功能的具体代码之前,先简单介绍一下涉及到的MFC的几个关键函数和机制。
windows应用程序的一切操作都是基于消息的,窗口及用户的各种行为都会触发对应的消息(例如左键单击、双击等等),每一种消息都会交由编写好的消息处理函数来进行处理。因此,我们应该为上面的每一项功能分别添加其对应的消息处理函数来实现。
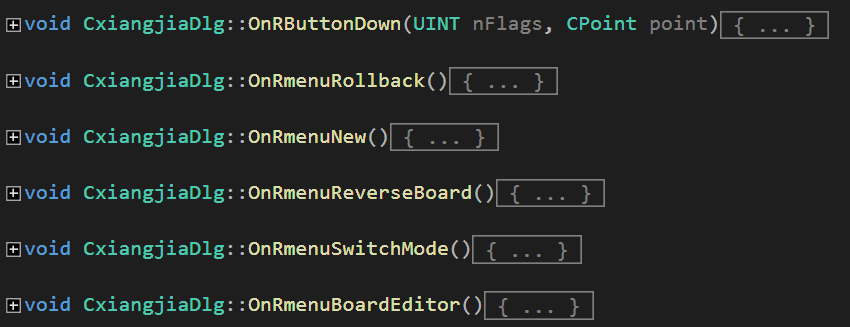
可以看到,上面的消息处理函数分别对应着按下右键、按下悔棋键、按下新游戏键、按下翻转棋盘键、按下模式切换键和按下棋盘编辑器键。
我们具体地来看一下另一个关键的函数,绘图函数。绘图函数用于在需要绘制窗口的时候实现窗口内图形的绘制。触发的场景包括程序运行开始,移动一颗棋子,翻转棋盘等等。这些操作执行后显示的界面都将发生变化,因此每次操作都应触发绘图函数。
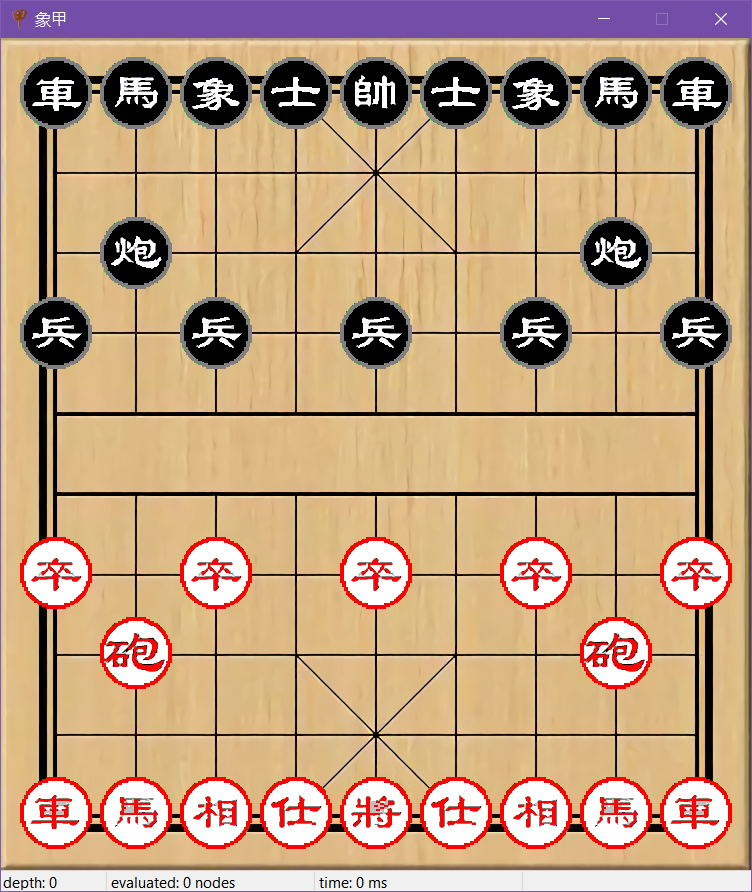
在显示的内容上,不仅需要显示棋局,为了更直观的提示用户,还应该有用户选中一颗棋子的标识,上一步走子的标识等等,这样才能避免用户下棋时摸不着头脑。另外,为了配合AI提示信息,我还为窗口添加了状态栏,显示AI的搜索参数。所有的元素的显示都体现在绘图函数中,给出绘图函数的具体代码。
void CxiangjiaDlg::OnPaint()
{
int i, j;
CPaintDC dc(this);
CDC MemDC;
CBitmap* pOldBmp;
POINT pt;
CBitmap bgBmp;
bgBmp.LoadBitmapW(IDB_BG);
CImageList chessmen_bmp;
chessmen_bmp.Create(IDB_CHESSMEN, 72, 14, RGB(0, 255, 0));
CBitmap tarBmp;
tarBmp.LoadBitmapW(IDB_TARGET);
CBitmap lastBmp;
lastBmp.LoadBitmapW(IDB_LAST);
CBitmap lastfromBmp;
lastfromBmp.LoadBitmapW(IDB_LASTFROM);
MemDC.CreateCompatibleDC(&dc);
pOldBmp = MemDC.SelectObject(&bgBmp);
//按照棋盘绘制棋子
for (i = 0; i < 9; i++)
{
for (j = 0; j < 10; j++)
{
if (!checkerboard[i][j])
{
continue;
}
if (!isReverseDisplay)
{
pt.x = 19 + (8 - i) * 80;
pt.y = 19 + (9 - j) * 80;
}
else
{
pt.x = 19 + i * 80;
pt.y = 19 + j * 80;
}
chessmen_bmp.Draw(&MemDC, checkerboard[i][j] - 1, pt, ILD_TRANSPARENT);
}
}
CRect rect;
GetClientRect(&rect);
dc.BitBlt(0, 0, rect.Width(), rect.Height(), &MemDC, 0, 0, SRCCOPY);
if (last_move.chess != none)
{
//标记上次移动的棋子
MemDC.SelectObject(&lastBmp);
if (!isReverseDisplay)
dc.TransparentBlt(14 + (8 - last_move.x) * 80, 14 + (9 - last_move.y) * 80, 82, 82, &MemDC, 0, 0, 82, 82, RGB(255, 0, 0));
else
dc.TransparentBlt(14 + last_move.x * 80, 14 + last_move.y * 80, 82, 82, &MemDC, 0, 0, 82, 82, RGB(255, 0, 0));
}
if (last_move_from.chess != none)
{
//标记上次移动的棋子的起点
MemDC.SelectObject(&lastfromBmp);
if (!isReverseDisplay)
dc.TransparentBlt(14 + (8 - last_move_from.x) * 80, 14 + (9 - last_move_from.y) * 80, 82, 82, &MemDC, 0, 0, 82, 82, RGB(255, 0, 0));
else
dc.TransparentBlt(14 + last_move_from.x * 80, 14 + last_move_from.y * 80, 82, 82, &MemDC, 0, 0, 82, 82, RGB(255, 0, 0));
}
if (activated_chess.chess != none)
{
//选中棋子
MemDC.SelectObject(&tarBmp);
if (!isReverseDisplay)
dc.TransparentBlt(14 + (8 - activated_chess.x) * 80, 14 + (9 - activated_chess.y) * 80, 82, 82, &MemDC, 0, 0, 82, 82, RGB(255,0,0));
else
dc.TransparentBlt(14 + activated_chess.x * 80, 14 + activated_chess.y * 80, 82, 82, &MemDC, 0, 0, 82, 82, RGB(255, 0, 0));
}
MemDC.SelectObject(&pOldBmp);
MemDC.DeleteDC();
bgBmp.DeleteObject();
tarBmp.DeleteObject();
//更新状态栏
CString str;
str.Format(_T("depth: %d"), depth);
mstatusBar.SetPaneText(0, str);
str.Format(_T("evaluated: %d nodes"), count);
mstatusBar.SetPaneText(1, str);
str.Format(_T("time: %lld ms"), t2 - t1);
mstatusBar.SetPaneText(2, str);
}
下面再介绍一个关键函数,棋子的选择。用户的走子依赖于屏幕的点击,因此程序应该需要可以得到用户点击位置的棋子,将点击的棋子映射到游戏引擎的棋盘上执行对应的操作。实现的方法是添加左键单机消息处理函数,获取到鼠标单击的坐标,并将坐标通过计算映射到棋盘的X和Y坐标上。
void CxiangjiaDlg::OnLButtonDown(UINT nFlags, CPoint point)
{
// TODO: Add your message handler code here and/or call default
//按下选择棋子
if ((point.x - 19) % 80 >= 0 && (point.x - 19) % 80 <= 72 && (point.y - 19) % 80 >= 0 && (point.y - 19) % 80 <= 72)
{
int px, py;
if (!isReverseDisplay)
{
px = 8 - (point.x - 19) / 80;
py = 9 - (point.y - 19) / 80;
}
else
{
px = (point.x - 19) / 80;
py = (point.y - 19) / 80;
}
if (px >= 0 && px <= 8 && py >= 0 && py <= 9)
{
if (player && isSameColor(player, checkerboard[px][py]))
{
activated_chess.chess = checkerboard[px][py];
activated_chess.x = px;
activated_chess.y = py;
refreshWindow();
}
}
}
CDialogEx::OnLButtonDown(nFlags, point);
}
在用户抬起左键时将进行走子操作,实现原理同上,获取左键抬起时的鼠标坐标,将选定的棋子移动到坐标位置,当然在移动前需要判断移动是否合法,这需要调用编写好的游戏引擎函数。在移动成功后还需进行胜利判断,如果游戏胜利则弹出胜利的提示对话框,否则继续进行游戏循环。
void CxiangjiaDlg::freeMode(CPoint point)
{
int tx, ty;
int isMoveSuccessfully;
int isEnd;
int tmpBoard[9][10];
if (activated_chess.chess != none)
{
if ((point.x - 19) % 80 >= 0 && (point.x - 19) % 80 <= 72 && (point.y - 19) % 80 >= 0 && (point.y - 19) % 80 <= 72)
{
if (!isReverseDisplay)
{
tx = 8 - (point.x - 19) / 80;
ty = 9 - (point.y - 19) / 80;
}
else
{
tx = (point.x - 19) / 80;
ty = (point.y - 19) / 80;
}
if (tx >= 0 && tx <= 8 && ty >= 0 && ty <= 9)
{
copyBoard(lastBoard, tmpBoard);
copyBoard(checkerboard, lastBoard);
isMoveSuccessfully = move(activated_chess.chess, activated_chess.x, activated_chess.y, tx, ty, checkerboard, 1);
if (isMoveSuccessfully)
{
t1 = 0;
t2 = 0;
count = 0;
depth = 0;
player = (player == red) ? black : red;
last_move_from = activated_chess;
last_move = activated_chess;
last_move.x = tx;
last_move.y = ty;
activated_chess.chess = none;
refreshWindow();
isAllowRollback = 1;
isEnd = isGameOver(checkerboard);
if (isEnd)
{
if (isEnd == red)
{
MessageBox(_T("红方胜!"), _T("象甲"));
}
else
{
MessageBox(_T("黑方胜!"), _T("象甲"));
}
INT_PTR nRes;
nRes = MessageBox(_T("要开始新游戏吗?"), _T("新游戏"), MB_YESNOCANCEL);
if (nRes == IDYES)
{
INT_PTR nRes;
CModeDlg modeDlg;
nRes = modeDlg.DoModal();
if (nRes == IDOK)
{
gameDlgIni();
}
refreshWindow();
}
}
}
else
{
copyBoard(tmpBoard, lastBoard);
}
}
}
}
}
以上简单介绍了部分GUI的功能的实现,更多源代码请下载工程文件查看。
经过上面的一番操作,我们已经可以在这个象棋程序上自己和自己下棋了,可以说,一个完整的象棋游戏到此已经实现好了。但是更重要的是AI对战,我们要让电脑成为一方,并且具备一定的实力与你进行象棋大战。
要想实现象棋AI,两部分必不可少,一是局面评估策略,二是搜索算法。
首先讲局面评估策略。由于象棋走子的可能性众多,即便是现在的计算机也难以穷尽所有的走法,所以需要设定一定的搜索深度,通过一定的局面评估策略来得到一个在限定搜索深度下的最优解,并返回这个解的第一步走法。最优解的目标是在限定深度下,尽可能使我方评分最大而让对方的评分最小,该目标的实现是搜索算法的范畴,这个一会再说。可以说局面评估策略的好坏决定着AI的聪明与否。
我把局面评估策略分为三部分。(具体评分参考了论文“中国象棋博弈局面评估研究罗涛”)
一是棋子本身的价值,比如车的价值大于马的价值大于兵的价值,以确定的子力价值评估局面,在下棋的时候自然是尽可能吃掉对方的子而自己的子不受损失为好。我设定的不同棋子的子力价值如下。
int getChessValue(const int chess, const int x, const int y)
//获取子力价值,输入:棋子类型,x坐标,y坐标
{
switch (chess)
{
case rche:
case bche:
return 600;
case rma:
case bma:
return 350;
case rpao:
case bpao:
return 400;
case rbing:
case bbing:
return 150;
case rxiang:
case bxiang:
return 300;
case rshi:
case bshi:
return 250;
case rjiang:
case bjiang:
return 1000;
default:
return 0;
}
}
二是棋子位置价值。光看子力价值还不够,因为忽略棋子的位置难以客观的评价整个棋局。例如,中路车、窝槽马显然对对方有更大的压制作用,评分应当提升,过河小兵也是如此。而边马离象等位置的棋子作用较低,不值得提倡。因此根据每种不同的棋子,设定了各自的位置价值进行更精细的评估。
int bingPositionValue[10][9] = {
{ 0, 0, 5, 5,10, 5, 5, 0, 0},
{ 5,10,21,30,42,30,21,10, 5},
{ 4, 8,18,26,37,26,18, 8, 4},
{ 3, 6,10,17,22,17,10, 6, 3},
{ 2, 4, 7, 8,12, 8, 7, 4, 2},
{ 1, 2, 4, 4, 7, 4, 4, 2, 1},
{ 0, 0, 1, 0, 2, 0, 1, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0}
};
int maPositionValue[10][9] = {
{ 5,10,15,12,15,12,15,10, 5},
{ 5,22,20,22, 7,22,20,22, 5},
{ 5,15,20,17,20,17,20,15, 5},
{ 5,17,20,22,20,22,20,17, 5},
{ 5,10,15,15,20,15,15,10, 5},
{-5, 0,-3, 1, 1, 1,-3, 0,-5},
{-5,-2, 0,-1, 1,-1, 0,-2,-5},
{-8, 0, 0,-4,-7,-4, 0, 0,-8},
{-5,-2, 0,-6,-4,-6, 0,-2,-5},
{-5,-5,-8,-10,-10,-10,-8,-5,-5}
};
int paoPositionValue[10][9] = {
{ 0, 0,-3,-3, 0,-3,-3, 0, 0},
{ 0, 2, 0, 2,-3, 2, 0, 2, 0},
{-3, 0, 0,-3,-3,-3, 0, 0,-3},
{ 0, 2, 0, 2, 0, 2, 0, 2, 0},
{ 0, 0,-3, 0, 0, 0,-3, 0, 0},
{ 0, 0, 0, 1, 1, 1, 0, 0, 0},
{ 0,-2, 0,-1, 1,-1, 0,-2, 0},
{ 0, 0, 0,-4,-4,-4, 0, 0, 0},
{ 0,-2, 0,-6,-4,-6, 0,-2, 0},
{ 0, 0, 0,-5,-5,-5, 0, 0, 0}
};
int chePositionValue[10][9] = {
{15,15,12,17,20,17,12,15,15},
{15,17,15,22,17,22,15,17,15},
{12,15,15,17,17,17,15,15,12},
{ 0, 2, 0,17,15,17, 0, 2, 0},
{10,10, 7,25,25,25, 7,10,10},
{10,10,10,26,26,26,10,10,10},
{ 0,-2, 0,14,14,14, 0,-2, 0},
{ 0, 0, 0,11,11,11, 0, 0, 0},
{ 0,-2, 0, 9,11, 9, 0,-2, 0},
{-10, 0, 0,10,10,10, 0, 0,-10}
};
int xiangPositionValue[10][9] = {
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{-10, 0, 0, 0,20, 0, 0, 0,-10},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0}
};
int shiPositionValue[10][9] = {
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0,10, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0}
};
int jiangPositionValue[10][9] = {
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0, 0, 0, 0, 0, 0, 0},
{ 0, 0, 0,-15,-10,-15, 0, 0, 0},
{ 0, 0, 0,-10,-20,-10, 0, 0, 0},
{ 0, 0, 0,10,30,10, 0, 0, 0}
};
int getPositionValue(const int chess, const int x, const int y)
{
switch (chess)
{
case rche:
return chePositionValue[y][x];
case bche:
return chePositionValue[9 - y][8 - x];
case rma:
return maPositionValue[y][x];
case bma:
return maPositionValue[9 - y][8 - x];
case rpao:
return paoPositionValue[y][x];
case bpao:
return paoPositionValue[9 - y][8 - x];
case rbing:
return bingPositionValue[y][x];
case bbing:
return bingPositionValue[9 - y][8 - x];
case rxiang:
return xiangPositionValue[y][x];
case bxiang:
return xiangPositionValue[9 - y][8 - x];
case rshi:
return shiPositionValue[y][x];
case bshi:
return shiPositionValue[9 - y][8 - x];
case rjiang:
return jiangPositionValue[y][x];
case bjiang:
return jiangPositionValue[9 - y][8 - x];
default:
return 0;
}
}
三是灵活性价值。中路车比未动的车拥有更高的灵活性,显然更容易应对战场局面的变化,因此下棋时讲究早出车。类似,被绊住马脚的马比灵活性高的马受到的牵制更大更不利。灵活性价值根据棋子可以达到的位置数量乘以不同棋子对应的参数得到。
int getFlexibilityValue(const int chess, int num)
{
switch (chess)
{
case rche:
case bche:
return 3 * num;
case rma:
case bma:
return 5 * num;
case rpao:
case bpao:
return 3 * num;
case rbing:
case bbing:
return 5 * num;
case rxiang:
case bxiang:
return 2 * num;
case rshi:
case bshi:
return 2 * num;
case rjiang:
case bjiang:
return 5 * num;
default:
return 0;
}
}
最后,局面评估的总分便是以上三项得分的总和。注意还需要用己方棋子的得分减去对方棋子的得分,这样才能评估我方的场面优劣。
int evaluate(const int ctrl_col, const int board[9][10])
//局面评估函数
{
int sum = 0;
int i, j;
int num;
for (i = 0; i < 9; i++)
{
for (j = 0; j < 10; j++)
{
if (!board[i][j])
continue;
num = 0;
moverablePositionCount(board[i][j], i, j, board, &num);
if (isSameColor(ctrl_col, board[i][j]))
{
sum += (getChessValue(board[i][j], i, j) + getPositionValue(board[i][j], i, j) + getFlexibilityValue(board[i][j], num));
}
else
{
sum -= (getChessValue(board[i][j], i, j) + getPositionValue(board[i][j], i, j) + getFlexibilityValue(board[i][j], num));
}
}
}
return sum;
}
讲完了局面评估,轮到了AI引擎的另一大关键,局面搜索算法。我这里采用的是alpha-beta算法。网上有大量关于该算法的详细介绍,我这里只是简单讲解并加以应用。局面搜索的目标是我方得分最大化而敌方得分最小化,在一定的搜索深度下,如果最深的深度处是我方,那么在所有轮到我方的深度时,都应该取得分最大的局面,但下棋时对方也不是傻子,因此在所有轮到对方的深度,应该取得分最小的局面,这就是极大极小值博弈算法,原理上十分简单。
为了搜索更深的深度,如果能对该算法生成的搜索树进行一定的剪枝剪去必定无用的节点,那么便可以加快搜索的速度且在相同时间内提升搜索的深度。具体的剪枝方法使用的便是a-b算法,它可以剪去一些必定不能对搜索结果造成影响的无需搜索的不必要节点,剪枝原理在这里不再详细赘述,分析搜索树便不难得到。
mark AlphaBeta(const int ctrl_col, const int board[9][10], const int searchDepth, const int currentDepth, mark alpha, mark beta, int* count)
//a-b算法(剪枝),输入参数:控制颜色,棋盘,搜索深度,当前深度(外部请设1),alpha值(外部请设最小值),beta值(外部请设最大值)
{
int oppo_col = (ctrl_col == red) ? black : red;
int i, j, n;
int moverableList[20][2];
int num = 0;
int fancyBoard[9][10];
mark result;
/*
if (isGameOver(board)) //一旦胜利直接返回极限评分,含结构风险
{
result.score = currentDepth % 2 ? (-10000 + (currentDepth - 1) * 100) : (10000 - (currentDepth - 1) * 100);
return result;
}
*/
if (currentDepth == searchDepth + 1) //到达叶子节点评估局面(其实评估的是上一层的局面)
{
result.score = currentDepth % 2 ? -evaluate(oppo_col, board) : evaluate(oppo_col, board);
//最底层是敌方,力求最小化;最底层是我方,我方力求最大化
return result;
}
(*count)++; //计数
for (i = 0; i < 9; i++)
{
for (j = 0; j < 10; j++)
{
if (!isSameColor(ctrl_col, board[i][j])) //只能操控本方棋子
continue;
moverablePosition(board[i][j], i, j, board, moverableList, &num); //更新棋子可走位置列表
for (n = 0; n < num; n++) //遍历可走位置
{
//快速胜利判断
if (board[moverableList[n][0]][moverableList[n][1]] == rjiang || board[moverableList[n][0]][moverableList[n][1]] == bjiang)
{
result.score = currentDepth % 2 ? (10000 - currentDepth * 100) : (-10000 + currentDepth * 100);
}
else
{
copyBoard(board, fancyBoard);
//接下来全部使用fancyBoard
move(fancyBoard[i][j], i, j, moverableList[n][0], moverableList[n][1], fancyBoard);
result.score = AlphaBeta(oppo_col, fancyBoard, searchDepth, currentDepth + 1, alpha, beta, count).score;
}
result.cx = i;
result.cy = j;
result.tx = moverableList[n][0];
result.ty = moverableList[n][1];
if (currentDepth % 2) //我方,力求得分最大化
{
if (result.score > alpha.score) //更新下限值alpha
{
alpha = result;
if (alpha.score >= beta.score) //剪枝
return alpha;
}
}
else //敌方,力求得分最小化
{
if (result.score < beta.score) //更新上限值beta
{
beta = result;
if (alpha.score >= beta.score) //剪枝
return beta;
}
}
}
}
}
return currentDepth % 2 ? alpha : beta;
}
在设计和测试的时候还应考虑到一个问题,在某些局势较为不利的情形下,AI可能会陷入重复连将的死循环,导致游戏无法正常进行,而连将在象棋对弈中是不被允许的。因此我们需要加入连将的触发判断,一旦发现连将行为则屏蔽掉该走法转而另外选取次优解。
连将触发判断(判断上上个局面与当前局面是否完全相同),若触发则回滚上一步操作,并屏蔽该走法,转而重新选取次优解。
if (isSameBoard(checkerboard, aiLastLastBoard)) //走了死循环棋
{
move(checkerboard[aiM.tx][aiM.ty], aiM.tx, aiM.ty, aiM.cx, aiM.cy, checkerboard);
alpha.score = INT_MIN;
beta.score = INT_MAX;
aiM = ShieldAlphaBeta(ai, checkerboard, depth, 1, alpha, beta, &count, aiM);
move(checkerboard[aiM.cx][aiM.cy], aiM.cx, aiM.cy, aiM.tx, aiM.ty, checkerboard);
}
ShieldAlphaBeta()中加入的屏蔽判断:
if (i == shield.cx && j == shield.cy && moverableList[n][0] == shield.tx && moverableList[n][1] == shield.ty) continue;
由于在搜索过程中可能一次会搜索百万种的局面,因此对代码的细微优化也可能极大的提升搜索速度从而带来收益,这一点我在实际优化过程中感触颇深。一开始从多态算法转为数值算法带来的速度提升是巨大的,后来将位置评估中引用的得分数组放到函数外面从而省去了每一次局部变量的创建和销毁同样瞬间减少了近一半的时间,还有很多处细节上的优化都在代码中有所体现。
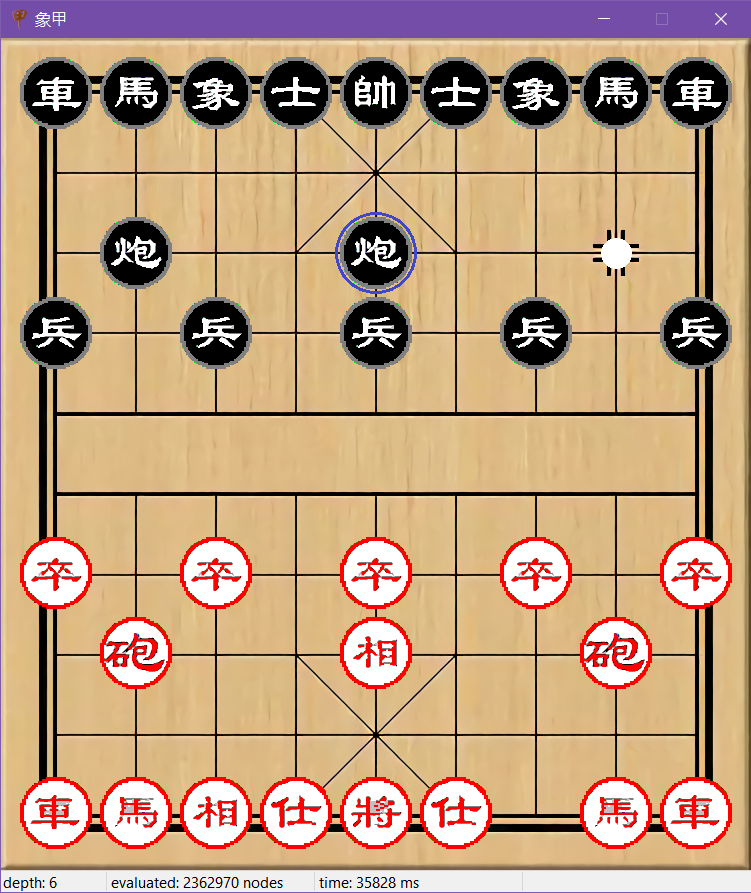
下表显示了不同搜索深度下程序在开局时的思考时间。
| Search Depth | Time Cost |
| 6 | 35828ms |
| 5 | 3016ms |
| 4 | 235ms |
| 3 | 16ms |
至此,象甲的设计和编写全部结束了,但是其实程序还有很多优化的空间,例如使用更加高效的算法如pvs算法,利用多线程发挥处理器多核的优势进行并行计算等等,未来可以继续改进。
这样一个程序熟练了我的C++技能,掌握了MFC编程的基本方法,学习了新的机器学习算法同时对中国象棋有了更深的理解。感谢大家,欢迎讨论并提出宝贵的意见。