使用scrapy爬取51job岗位需求信息并生成词云
本文基于scrapy爬虫框架爬取岗位需求信息,利用jieba库中文分词后统计词频,最终使用wordcloud生成词云。本文需要一定的scrapy框架基础知识。
最近学习了scrapy框架,使用框架的好处是它帮你实现了大部分爬虫的常用功能比如下载和常用数据格式的解析,还有内部默认已经实现了多线程和url去重等功能,十分方便,可以迅速的完成爬虫的设计和实施。缺点是框架毕竟是框架,结构比较固定不够灵活,如果想实现一些个性化的功能操作上会受到很大限制。
回到本次的程序。首先分析51job网站信息,查看搜索界面网页布局和对应url结构。
全文搜索关键词python,对应的url:
” https : // search.51job.com / list / 000000 , 000000 , 0000 , 00 , 9 , 99 , python , 2 , 1 . html ? lang=c & stype= & postchannel=0000 & workyear=99 & cotype=99 & degreefrom=99 & jobterm=99 & companysize=99 & providesalary=99 & lonlat=0%2C0 & radius=-1 & ord_field=0 & confirmdate=9 & fromType= & dibiaoid=0 & address= & line= & specialarea=00 & from= & welfare= “
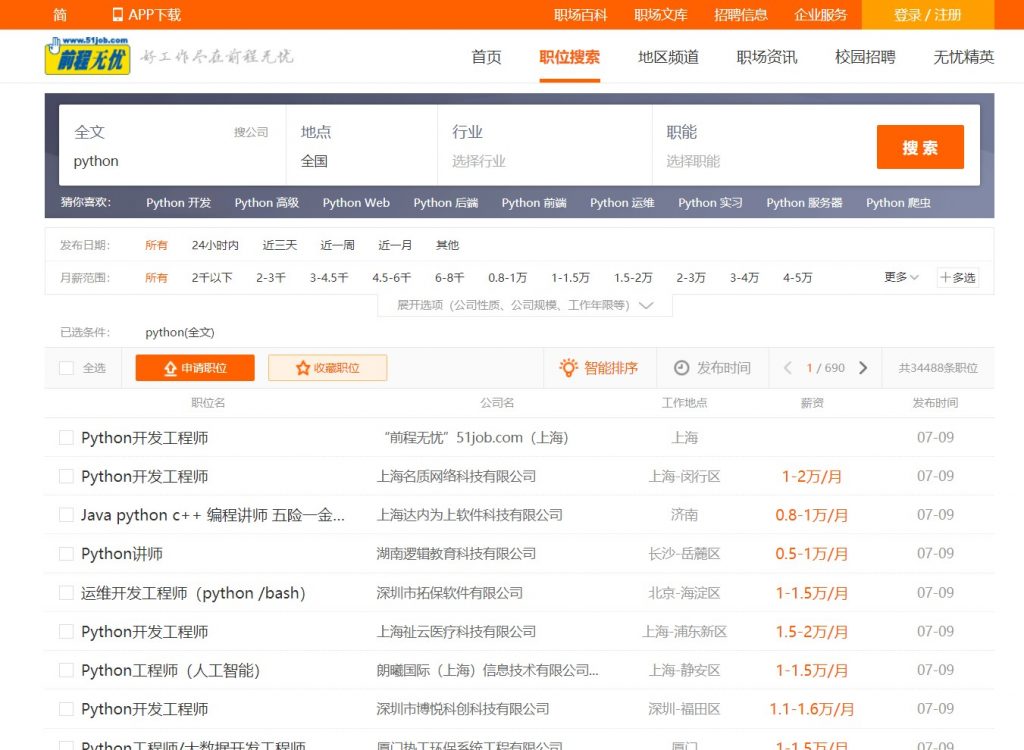
简单分析后不难看出,逗号参数中倒数第三个为关键词,最后一个数字是页码,其余的数字参数和后缀的查询参数都是其他搜索限定条件,这里先不管。
因此爬取的第一步是拿下搜索结果页码,第二部抓到职位详情对应的链接,第三步获取岗位信息并做进一步处理。
基于scrapy框架的特性,使用CrawlSpider类框架十分合适,它可以帮我们自动提取需要的链接并跟进处理,省去翻页和解析链接等许多麻烦的操作。
CrawlSpider关键在于编写rules链接提取规则,LinkExtractor()会帮我们自动获取到页面中的所有超链接,我们只需要基于这些链接编写正则表达式提取出需要的即可。
根据之前分析的翻页url结构和职位详情链接结构,写出对应的Rules。其中不用担心挖到重复的url,因为scrapy内部自带有去重功能,遇到重复链接会自动舍弃不再调用回调函数。
self.rules = (
#自动翻页
Rule(LinkExtractor(allow=(self.start_urls[0][:-6] + '\d+\.html\?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=$',)),
process_links=self.link_processor, follow=True),
#自动挖掘详情页url
Rule(LinkExtractor(allow=('https://jobs\.51job\.com/.*\?s=01&t=0$',), deny=('https://jobs.51job.com/all/.*',)), callback=self.parseInfo)
,)
其中process_links参数是自己写的额外的链接处理函数,这里用于控制链接数量,限制抓取页数;follow参数指定是否继续跟进访问链接,这里翻页链接为True,继续访问抓取详情页url。
def link_processor(self, links):
'''限制页面链接数量'''
resLinks = []
for link in links:
if int(re.findall(',(\d+)\.html', link.url)[0]) <= 100:
resLinks.append(link)
return resLinks
上面的函数用于限制页面数量,这里设为100页,每页有50条数据,总共抓取5000条岗位信息。
接下来用详情页的回调函数进行岗位信息抓取。拿到岗位信息后使用jieba库分词并手动统计词频,函数返回字典格式的当前页面的词频统计结果。
def parseInfo(self, response):
'''挖掘详情页职位信息'''
text_list = response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p//text()').extract()
resItem = Job51Item()
pos = resItem['word_frequency'] = {}
for text in text_list:
for word in jieba.cut(text):
if self.isValidStr(word):
pos[word] = pos.get(word, 0) + 1
yield resItem
def isValidStr(self, strs):
'''判断字符串长度,是否包含中文或字母'''
if len(strs) < 2:
return False
if strs.isalnum() and not strs.isdigit():
return True
for _char in strs:
if '\u4e00' <= _char <= '\u9fa5':
return True
return False
isValidStr()函数用于筛选掉一些无用的词,比如单字及纯数字,保留其他英语单词和带有中文汉字的结果。
得到item结果后,进入添加pipeline进行进一步的处理,主要是统计总的累计词频和生成词云。
class Job51Pipeline:
def __init__(self):
self.total_word_frequency = {}
def process_item(self, item, spider):
for key, value in item['word_frequency'].items():
self.total_word_frequency[key] = self.total_word_frequency.get(key, 0) + value
# with open('out_result.txt', 'w') as f:
# f.write(str(self.total_word_frequency))
return item
def __del__(self):
with open('out_result.txt', 'w') as f:
f.write(str(self.total_word_frequency))
wdcld.generate_wordcloud()
最后是词云生成。词云使用wordcloud库,由于其对英文支持较好,而不支持中文词频统计,因此我们手动统计词频后调用fit_words()函数传入词频字典直接生成词云而跳过最常用的generate()函数的自动词频统计。
import wordcloud
def generate_wordcloud(del_most_words=15, width=1000, height=500):
with open('out_result.txt', 'r') as f:
freq = eval(f.read())
freq = sorted(freq.items(), key=lambda x: x[1], reverse=True)
for i in range(del_most_words):
print(freq[i])
freq = freq[del_most_words:]
wdc = wordcloud.WordCloud(font_path='msyh.ttc',
width=width,
height=height,
).fit_words(dict(freq))
image = wdc.to_image()
image.show()
if __name__ == "__main__":
generate_wordcloud(0, 1000, 500)
这里我还添加了一个额外功能。由于出现频数最大的词语往往是一些交流常用词,这对我们生成的结果没有特别的参考价值,因此可以去除一部分频数最高的词语。
最后放上python关键词的词云结果。

最后我还使用同样的方法试图爬取 ZHI lian招聘,然而它的职位数据使用了js动态渲染+post请求使用签名加密认证的方式反爬虫,一般的方法很难破解。
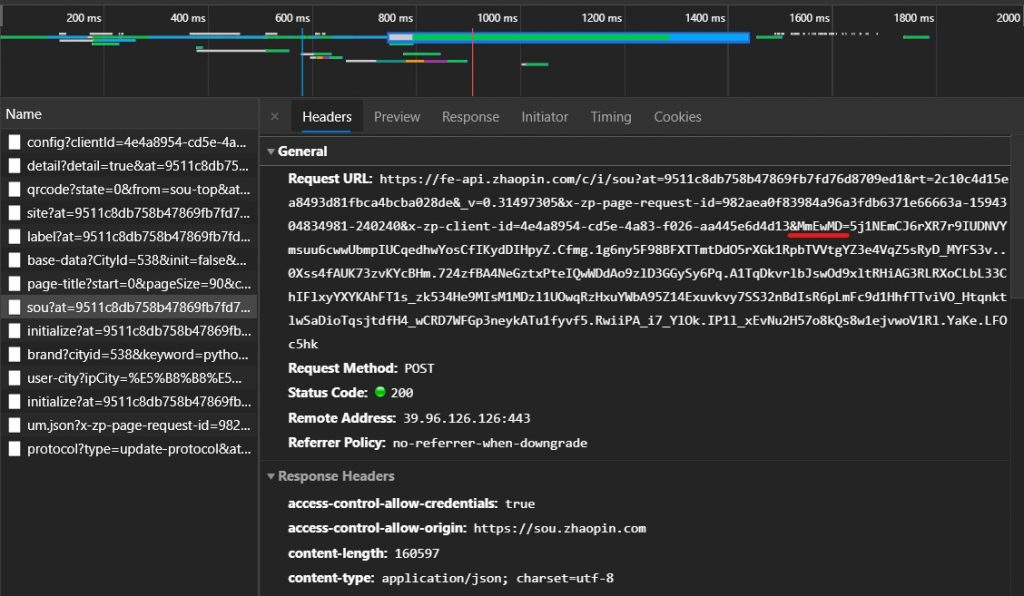
其中的参数MmEwMD就是罪魁祸首,由js动态生成的数字签名。
面对这种难缠的对手,果断上selenium,使用headless浏览器。然而直接访问依旧碰壁,后台请求403不返回任何数据,显然对手也想到了这一招。
最终还是找到了方法,对方采用判断浏览器navigator.webdriver的方法检测自动化,正常浏览器为undefined,自动化时为True,因此在启动driver后重赋值这个参数。
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
});
"""
})
加入这段代码浏览器会在每次加载页面前执行给定的js,从而破解判断。
最后终于看到了久违的数据。