从零讲述人工神经网络
本文从最基本的二维线性分类器出发,从零讲述全连接人工神经网络(Artificial Neural Network)的基本原理、组成结构、信号传递,以及我们如何对它进行训练,帮助读者从头彻底厘清神经网络的概念和搭建过程。
本文是MUDSS Workshop系列的文字改写版,有关本次workshop的内容材料,欢迎查阅GitHub Repo。
文章目录
从简单线性分类器说起
线性分类器(Linear Classifier)是神经网络的基石,让我们先考虑一个简单的二维线性分类任务。
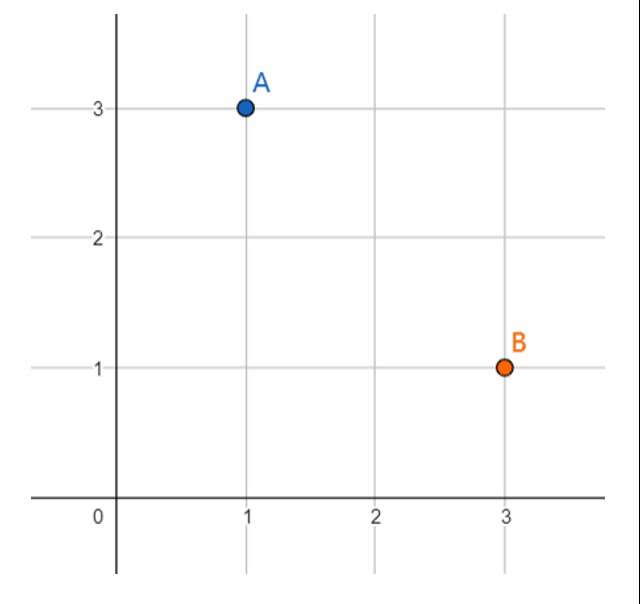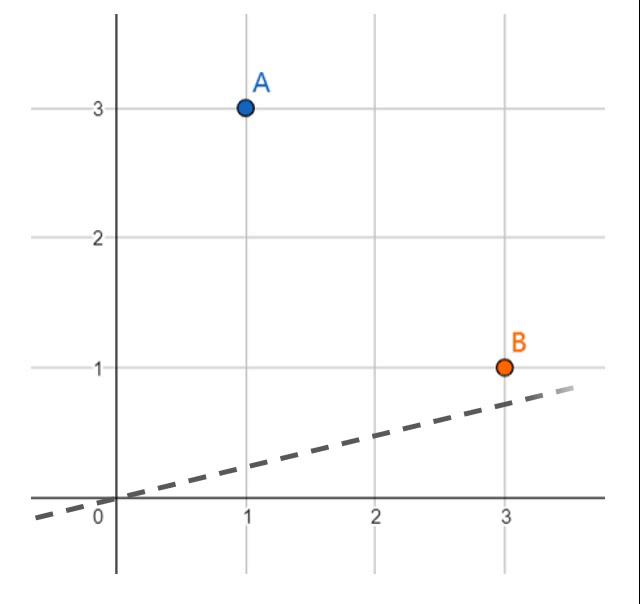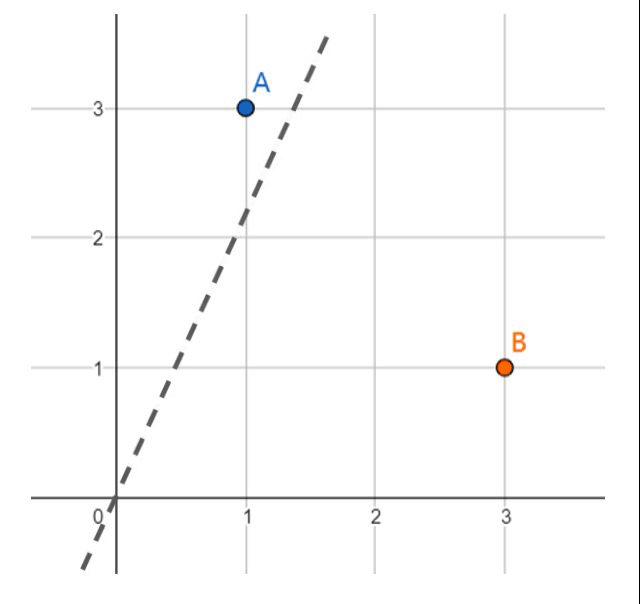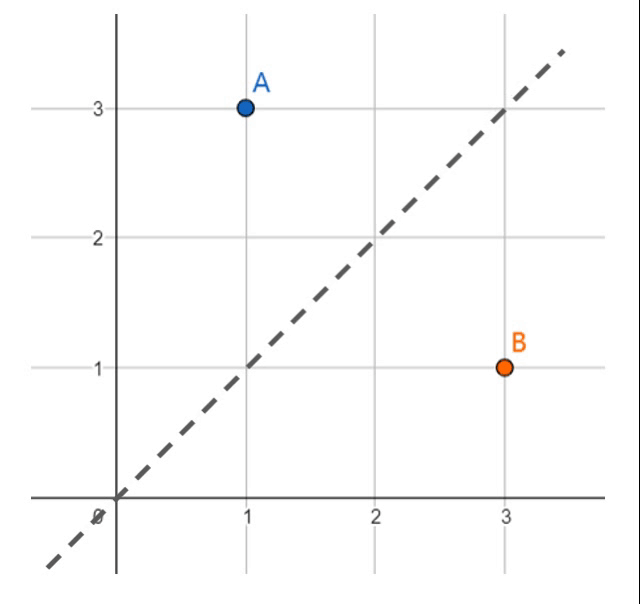
假定两个数据点\(A(1,3)\)和\(B(3,1)\)分属于两个不同的类,我们需要在平面上寻找一条能正确划分它们的直线。如果我们假设我们要找的直线恒过原点,那么唯一可以改变的参数只有直线的斜率\(k\)。
现在让我们从一台计算机的角度考虑这个问题。起初,我们并不知道\(k\)是多少,因此我们可以选择一个随机值作为出发点。观察上面的动画,显然,一开始的斜率过小,导致无法正确分开点\(A\)和\(B\)。现在我们开始调节初始斜率,一个简单且一步到位的方法是,令直线迫近点A,这样便可以正确的完成分类任务。但显然这么做仍不够好,这样粗暴的调节很容易让分割线紧挨着数据点,导致一个并不理想的答案。因此,我们可以以一个较小的步伐迈向新的数据点\(B\),最终得到一个我们期望的分类答案。我们之后会看到,这个步伐的大小称之为学习率(Learning Rate)。
组合多个线性分类器
让我们再来看另一个例子。
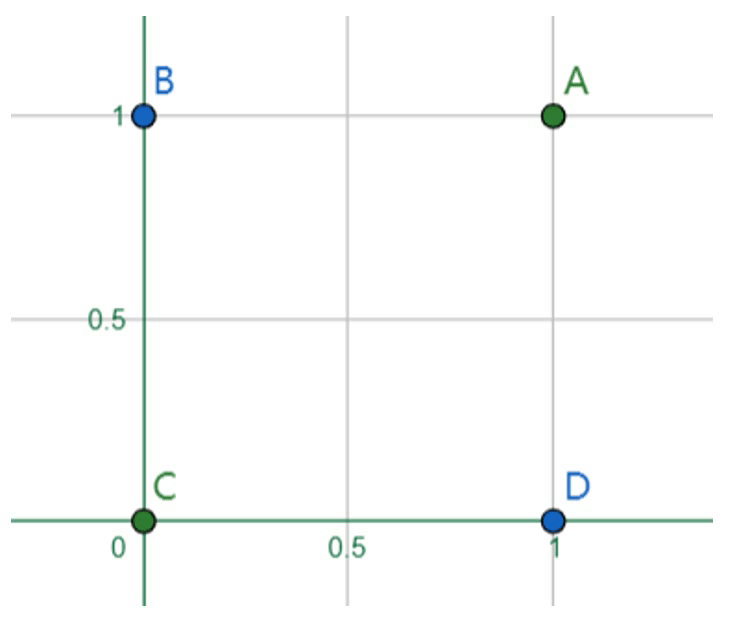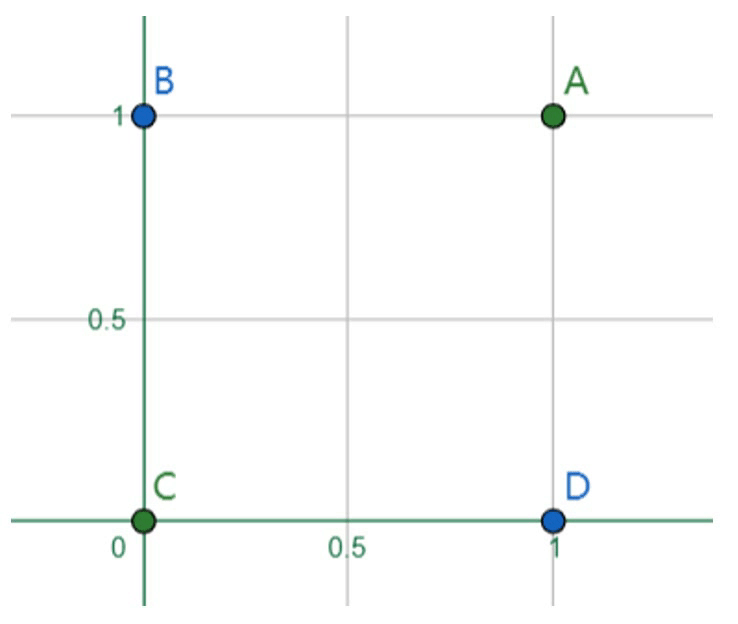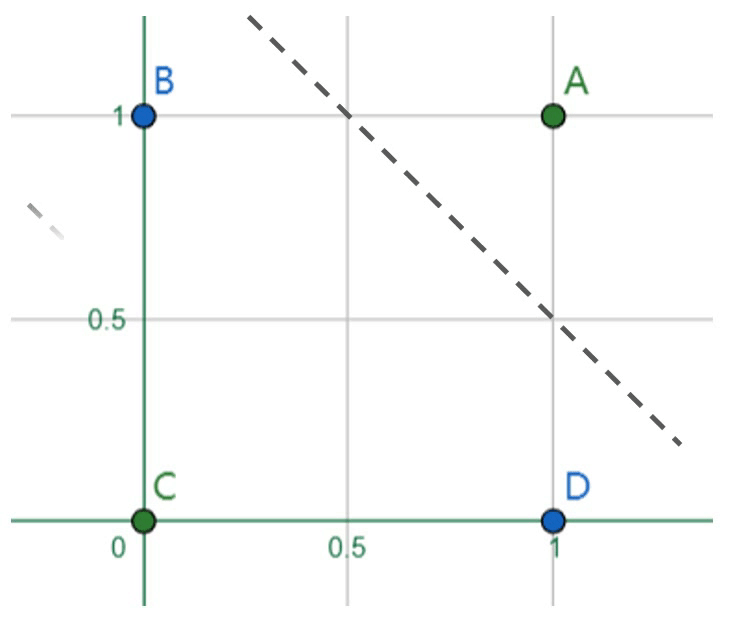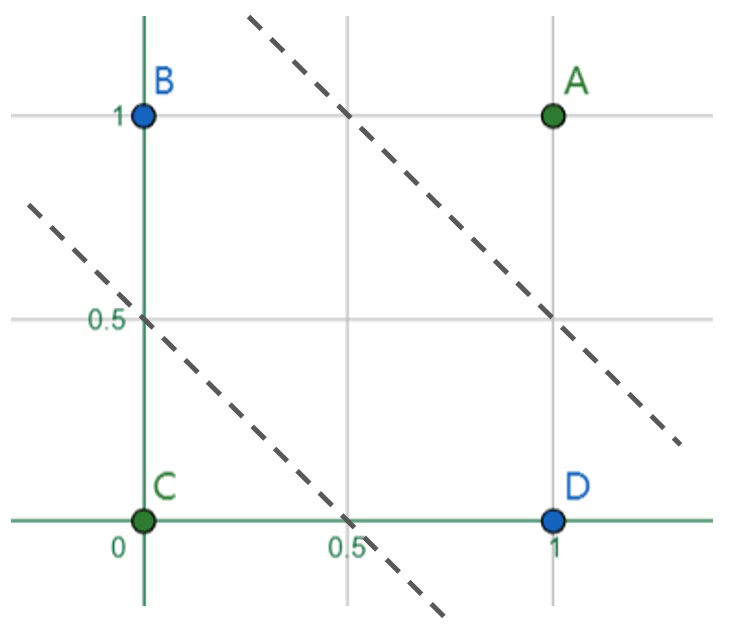
已知四个数据点\(A,B,C,D\)分属于两类,需要寻找能正确划分类\(A,C\)和类\(B,D\)的线性分类器。显然,在这个例子中我们无法用一条直线来区分两个类,但我们仍然希望使用线性分类器。因此有了新的解决方案:添加一条新的直线到坐标系中,两条直线共同工作将二维平面分割为三个区域,中间区域属于类\(B,D\)而对角区域属于类\(A,C\)。
可以想象,若我们添加更多的直线,就可以将平面分割为任意复杂的多边形区域,从而完成更复杂的分类任务。而这便是人工神经网络的基本思想,即通过大量线性分类器的组合,实现从输入空间到输出空间的复杂映射。
神经元与激活函数
在继续深入探讨之前,让我们回归自然,观察人工神经网络的关键启发灵感:神经元(Neuron)。
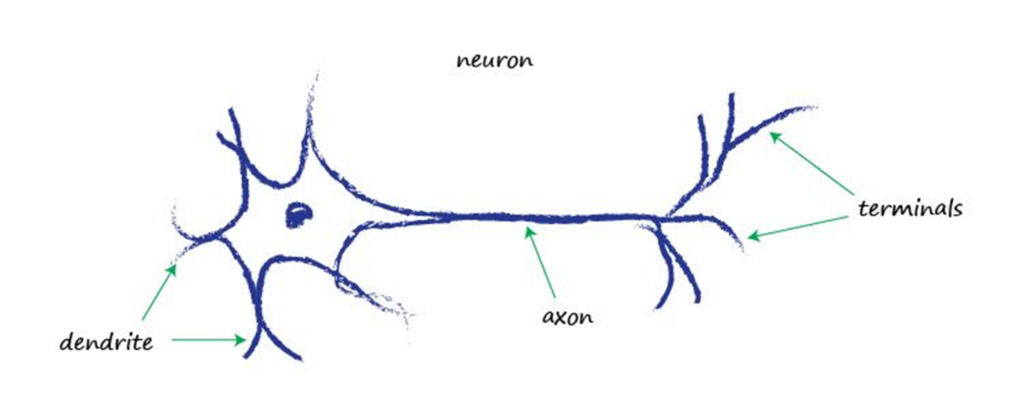
自然界中,不同动物的神经元的结构多种多样,但大多数都有一个最基本的功能特点:传递电信号。电信号总是从神经元的一端传递到另一端,且可以有多处输入信号,经过组合后输出至后续的多个神经元。重新回顾之前的线性分类器,你会发现它们在数学和逻辑上有着天然的共性。它们都承载着最基础简单的工作,不需要复杂的计算,但可以进行组合从而共同完成更复杂的任务。
人类上亿的神经元帮助我们感知声光电,具有情感、语言并可以独立思考,但自然界中也不乏简单的微生物,即使仅有少量的神经元组合也可以完成基本的觅食、分裂等任务。那么大量人工组合的线性分类器在数学上能否具有同样的能力呢?数学家已然证明了这个事实,我们也不妨一试。
然而,仅靠单纯的线性分类器的组合还不够。自然神经元的另一个显著特征是信号的激发。
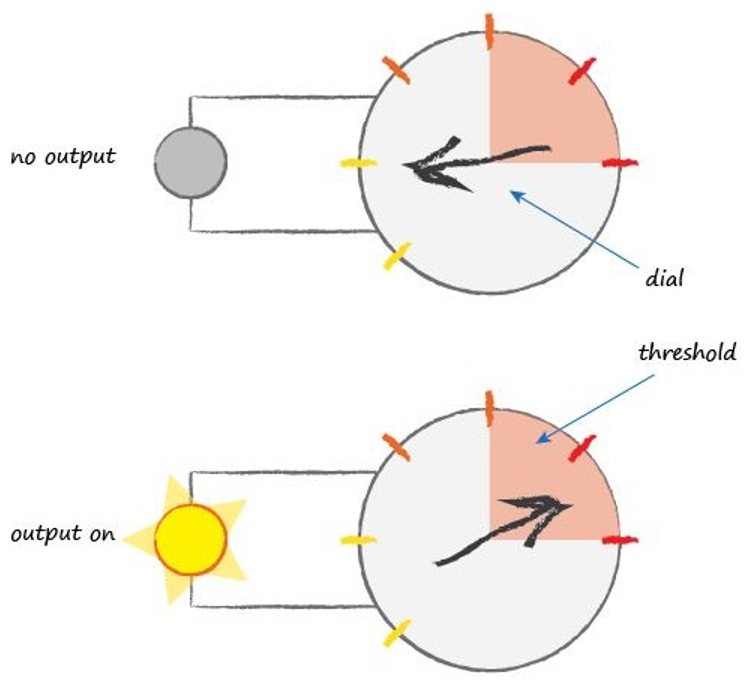
自然神经元会天然的抑制输出,而只有当输入达到一定强度,即到达一个阈值时,才会激发输出信号。这一特征可以十分有效的抑制噪声信号,使神经元仅仅响应相当强度的有意识的神经信号,从而避免引发频繁的错误波动。基于这一特点,我们也可以给人工神经元增加一个类似功能的机制,称作激活函数(Activation Function)。
激活函数的作用和激发输出的效果类似,其本质是一个函数,特性是只有当输入达到一定的大小时,才会产生相应的输出,否则输出信号将被有意地抑制。
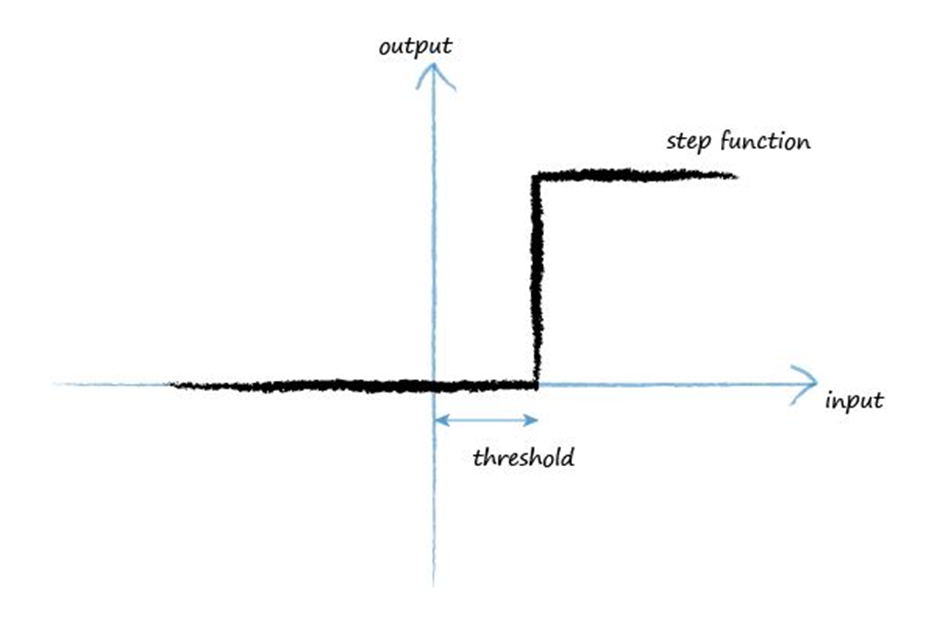
上图是一个遵循激活函数想法的阶跃函数(Step Function),当输入达到一个阈值(Threshold)时,才会产生一个正的输出值。
然而,阶跃函数的输出变化是随着输入的增大在瞬间发生的,这种不连续的特性使它难于准确表达输入与输出之间的关系,造成信息的丢失,且非常不利于以后的模型参数优化。由于函数不连续,我们无法对函数进行连续的积分或求导,这阻碍了数学计算的进行。
因此我们进一步对激活函数进行优化,得到一条更为优雅的曲线,Sigmoid函数。
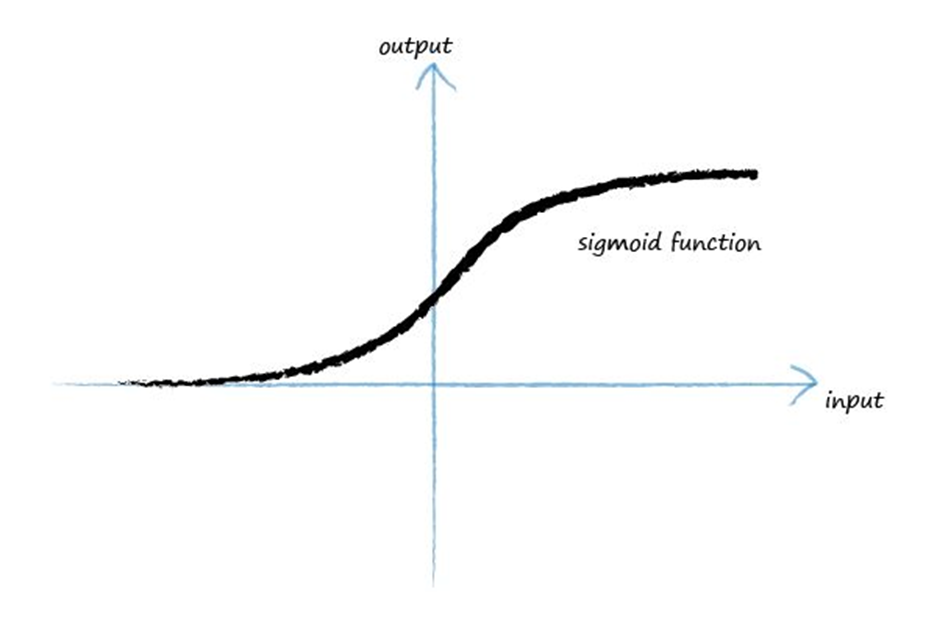
Sigmoid函数舍弃了不连续的跳变,使之更为优雅且适合于计算。除此之外,它并没有失去激活函数最关键的特性:激发输出。我们可以看到,虽然函数图像连续,但Sigmoid对较小的输入值极不敏感,函数变化基本发生在\(0\)值附近,仍然可以起到“激活”的作用。
$$y=\frac{1}{1+e^{-x}}$$
这是Sigmoid函数的计算公式,有一个印象就好,之后的计算我们会使用到它。
人工神经元
有了自然神经元的启发,我们将线性分类器和激活函数相结合,组成期望的人工神经元。
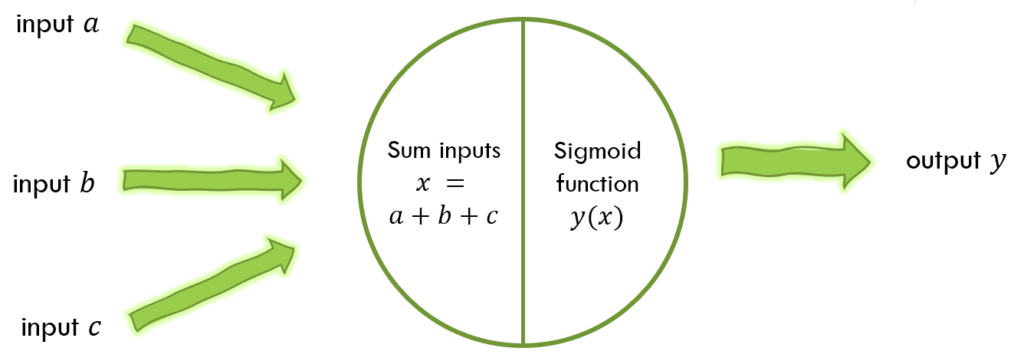
为了便于描述,我们假设有三个输入信号。对于一个人工神经元,我们要做的仅仅是将它们的值求和,再对结果应用Sigmoid激活函数,便得到了最后的单个输出。
人工神经网络
继续回顾之前的想法,一个线性分类器能发挥的作用微不足道,但我们可以将多个分类器进行组合以完成更高级的任务。人工神经元也是如此,我们可以添加更多的神经元,将所有的输入信号分别传输给每一个神经元,再由每一个神经元各自输出一个结果,这样一种结构称之为人工神经网络的一层(Layer)。在此基础上,我们还可以添加多个层,另前一层每个神经元的输出作为下一层神经元们的输入,于是便形成了一个具有多层连接(Connections)的人工神经网络(Artificial Neural Network)。
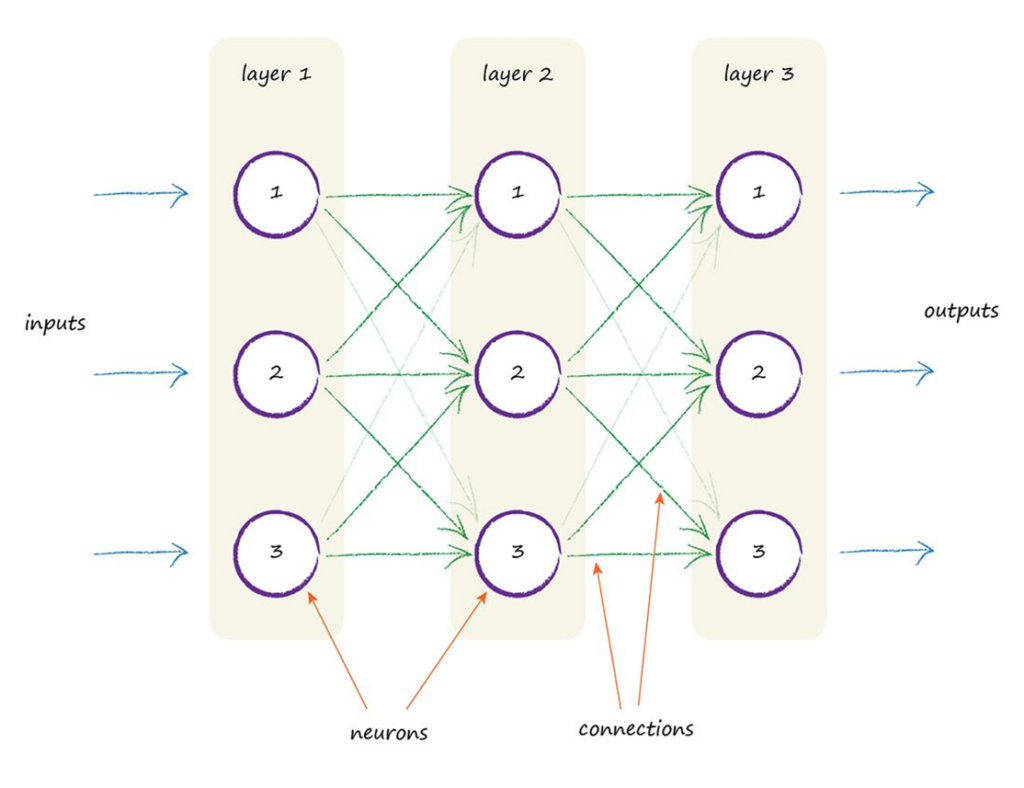
在以上结构中,每一层中的每一个神经元也可以称作神经网络中的一个节点(Node),每个节点都与它所在的前一层和后一层中的所有节点互相连接,形成一个具备通用性的全连接神经网络(Fully Connected Neural Network)。
现在,我们已经搭建起了一个神经网络的基本结构,为神经元节点建立了连接。但目前的神经网络仍有一个巨大的不足,它无法进行学习。对于任意给定的输入,这个复杂的网络只能计算得到一个确定的输出,使我们无法根据期望的输入输出对其进行训练,使之满足需求。这显然不是我们想要的。
事实上,我们的模型可能并不需要节点间全部的连接,一些输出可能仅对一部分输入信号极其敏感,而另一些输入几乎不对结果产生影响。基于此,我们可以给网络中的每一条连接增加一个参数,即连接的强度,或权重(Weights)。让它来控制这条连接上允许通过的信号的强弱。具体的,令权重值与对应连接的前一层节点的输出值相乘,把得到的新的结果传递至下一层。
在下图中,\(w_{i,j}\)表示前一层的节点\(i\)与后一层的节点\(j\)之间的连接的权重。
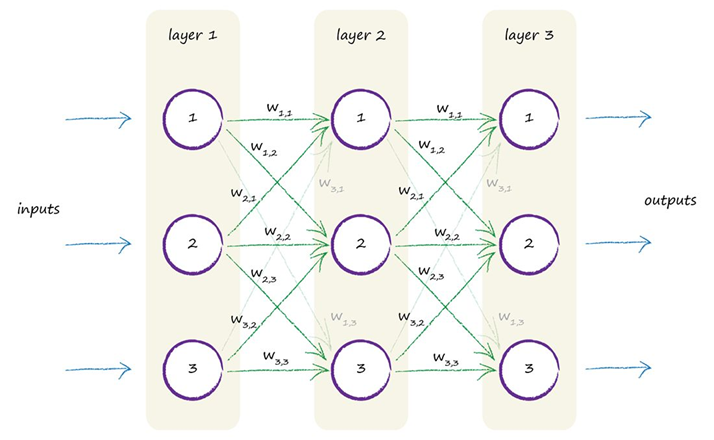
之后我们会看到,在实际训练过程中,我们并不需要手动设置每个权重的值,而是通过一些方法自动调节权重,让每个信号在传递过程中具有特定的强度,从而让最终的输出信号在给定输入时趋近于预期结果。于是,我们便成功的让神经网络具备了学习能力。
基于此,我们还可以发现,权重的存在另全连接神经网络具备极佳的泛用性。倘若网络中的一些权重为\(0\),则表示那些权重所对应的连接不存在。我们便因此获得了创建具有任意连接方式的人工神经网络的能力。
通用近似定理
人工神经网络结构的正确性和有效性已经得到了科学的证明,事实上,它可能远比我们想象的更加强大。
通用近似定理(Universal Approximation Theorem)告诉我们,当给定合适的权重时,人工神经网络可以表示一系列广泛的函数映射关系。更具体来说,只要具备足够的深度和节点数,神经网络能够很好的逼近两个欧几里得空间之间的任意连续函数。
而更具魅力的元素在于,我们甚至无需理解网络内部信号传递的具体工作原理,便可以利用人工神经网络解决复杂的任务。就如同人类至今仍无法完全揭示大脑的秘密,却丝毫不会影响大脑的思考,并能创造出辉煌灿烂的文化。
最终的人工神经元
理解了权重的概念和整个神经网络的结构,让我们重新回到单个神经元层面,更新对原先计算方式的认知。其实我们要做的,只是为输入添加权重值,就像在神经网络中做的一样。
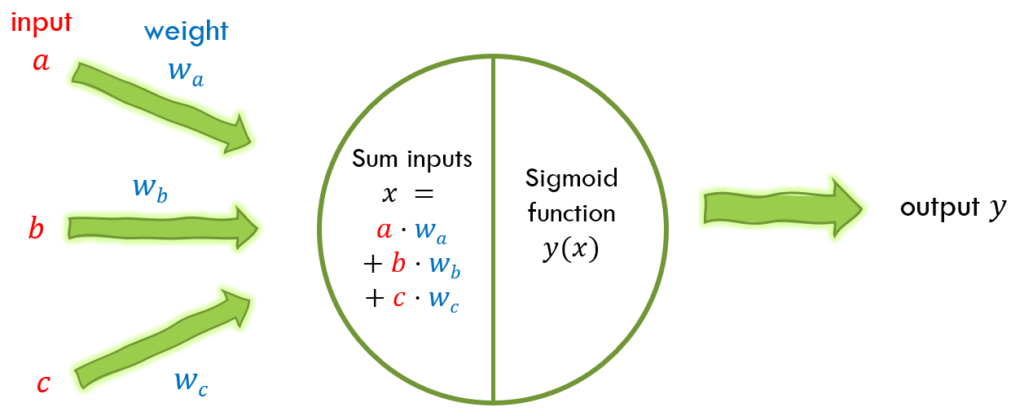
在对输入信号进行组合时,我们现在计算每一对输入与对应权重的乘积的和。现在我们可以把这整个神经元的计算过程概括为一个简短的公式。
$$y = sigmoid(\sum_i{x_i \cdot w_i}) = \frac{\sum_i{x_i \cdot w_i}}{1+e^{-x}}$$
其中\(x_i\)是第\(i\)个输入信号,\(w_i\)是对应的权重值。
前馈信号与矩阵乘法
信号由输入开始传递,依次经过各层,最终到达输出的过程叫做神经网络中信号的前馈传递(Feedforward Signal)。我们已经清楚的了解了信号在每一个神经元节点处的计算过程,因此也可以很容易的完成一次完整的计算。为了更直观的理解,我们进一步将模型简化为一个仅包含两层,每层两个节点的小型神经网络。
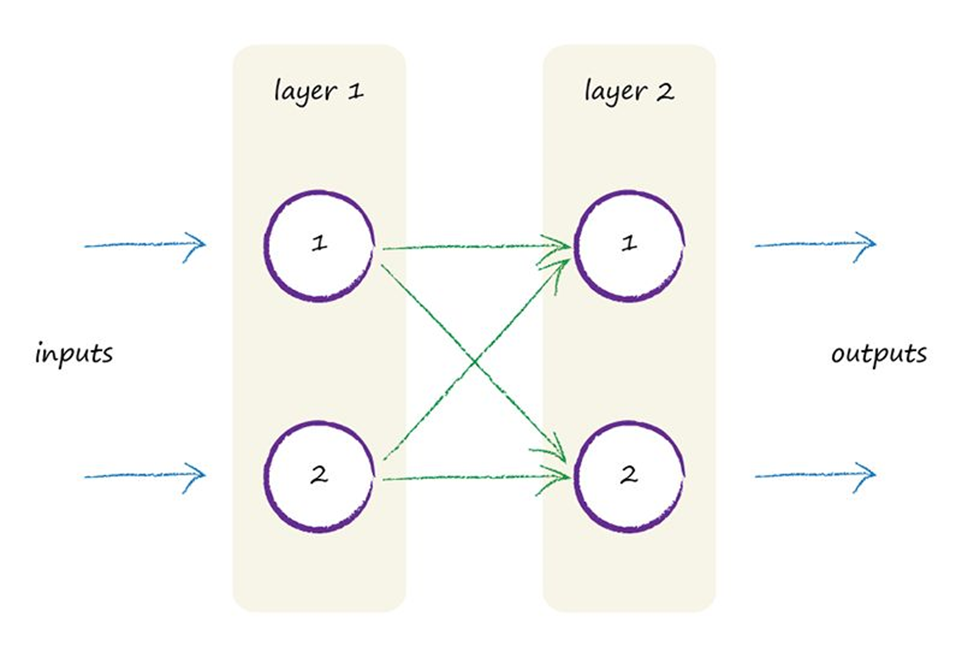
为了模拟计算,让我们把目光暂时聚焦到第二层。假设进入第2层每个节点的输入信号分别为\(input_1\)和\(input_2\),节点间的四个权重值按照之前的命名规则称为\(w_{1,1},w_{1,2},w_{2,1},w_{2,2}\),那么两个最后输出值可以表示如下。
$$ output_1 = sigmoid(input_1 * w_{1,1} + input_2 * w_{2,1}) \\ output_2 = sigmoid(input_1 * w_{1,2} + input_2 * w_{2,2}) $$
让我们仔细观察sigmoid函数内的部分,我们将每一个输入和对应的权重相乘再相加,这样的计算形式多么类似于数学中的矩阵乘法(Matrix Multiplication)运算。
不妨把所有的权重值表示为一个权重矩阵,每一列包含所有连接到前一层某个节点的权重,每一行包含所有连接到后一层某个节点的权重,再将所有输入转换为一个列向量,尝试对它们进行矩阵乘法运算。
$$ \begin{pmatrix}\ w_{1,1} & w_{2,1} \\ w_{1,2} & w_{2,2} \end{pmatrix} \begin{pmatrix} input_1 \\ input_2 \end{pmatrix} = \begin{pmatrix}\ input_1 * w_{1,1} + input_2 * w_{2,1} \\ input_1 * w_{1,2} + input_2 * w_{2,2} \end{pmatrix} $$
这与我们想要的结果完全一致!矩阵乘法极大的简化了前馈信号计算的表示方法,使我们可以将一个统一的计算格式编码成计算机语言,而无需考虑矩阵的大小和内部元素数量。因此我们找到了一个万能的钥匙来表达具有任意节点数量的人工神经网络的计算过程。
最终,我们可以把前馈信号计算过程中任意相邻两层间的计算概括为:
$$ O = sigmoid(W \cdot I) $$
其中,\(W\)是权重矩阵,\(I\)是一维输入信号矩阵,\(O\)是得到的一维结果矩阵。其中,这里的\(sigmoid\)函数被应用到矩阵中的每一个值上。
误差反向传播
现在我们已经学会了如何计算前馈信号,给定输入和一组权重,可以很容易的计算得到一组输出信号。然而在真实的机器学习应用中,我们希望对模型进行训练,使之能够拟合期望的输入输出。因此下一步要做的,就是在已知输入和预期输出的条件下,想办法得到正确的权重值。
然而,神经网络模型本身实在是太复杂了,全连接的特性决定了网络中涉及大量待定的权重信息,我们很难找到一种数学方法直接求解正确的权重。但我们能做的,是从一组随机的初始权重开始,逐渐优化权重值使输出迫近想要的结果。回顾最开始的二维线性分类器的例子,一开始我们并不知道正确的斜率是多少,但依据平面上其他坐标点给出的已知信息,我们得以优化斜率,最终得到想要的答案。在人工神经网络中,这一过程的思想也是一样的。
首先要做的,是定义一个损失函数(Loss Function),即表示当前模型的输出与预期输出之间的距离的大小,损失函数的计算结果也称作误差值(Error)。我们训练神经网络的目标便是通过改变权重值来最小化损失函数,使输出结果符合预期。损失函数的定义方式有很多种,这里我们选择比较基本的平方误差。
让我们仍然使用之前的2层简单神经网络,来做更详细的解释。
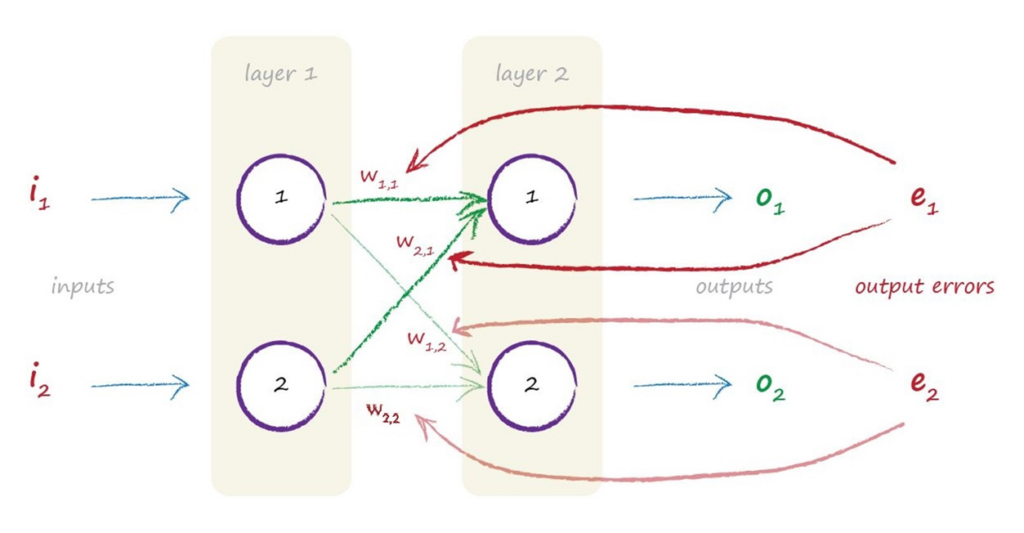
假设在信号前馈时,神经网络最后一层第\(k\)个节点的输出为\(o_k\),预期的正确输出结果为\(t_k\),则相应的第\(k\)个节点处的误差\(e_k\)表示为:
$$ e_k = {(t_k – o_k)}^2 $$
即两个结果之间差的平方。然而仅仅知道最终的误差值还不够,由于连接权重遍布整个神经网络,我们还需要知道网络中每一层的误差,并在之后以此为指导更新每一层的权重信息。
因此,有了最后一层的节点误差后,我们会据此从后往前依次计算每一层的误差。具体的,依照连接到下一层各个节点的权重的大小,拆分误差,并在前一层中按照节点之间的连接重新组合拆分的权重,以此计算得到前一层中各个节点的误差值。
观察上面的例子,假设第一层第\(k\)个节点的误差表示为\(e_k^{\prime}\),则遵循误差拆分的思想,可以计算其第\(1\)个节点的误差为:
$$ e_1^{\prime} = e_1 \cdot \frac{w_{1,1}}{w_{1,1}+w_{2,1}} + e_2 \cdot \frac{w_{1,2}}{w_{1,2}+w_{2,2}} $$
类似的,无论我们的神经网络有多少层,我们都可以继续重复以上过程,根据后一层的误差拆分计算得到前一层各节点的误差,直到到达输入层,我们将这一过程称为误差的反向传播(Backpropagation of Loss)。
再次使用矩阵乘法
参照之前前馈信号的计算,我们很容易发现,误差的反向传播同样适用于矩阵乘法。让我们将参与计算的权重比例和下一层误差分别表示为矩阵形式,则上例中前一层的误差可以表示为:
$$ e^{\prime} = \begin{pmatrix} \frac{w_{1,1}}{w_{1,1}+w_{2,1}} & \frac{w_{1,2}}{w_{1,2}+w_{2,2}} \\ \frac{w_{2,1}}{w_{1,1}+w_{2,1}} & \frac{w_{2,2}}{w_{1,2}+w_{2,2}} \end{pmatrix} \cdot \begin{pmatrix} e_1 \\ e_2 \end{pmatrix} $$
进一步观察上面的式子,虽然权重比例矩阵中的分母并不完全相同,但它们在计算中起到的是归一化的作用。换言之,省略分母会改变得到的误差值的大小,但并不会影响误差的正负方向。后面我们会看到,在使用误差来优化权重的过程中,实际上我们关注的仅仅是误差的方向而并非一个准确的值。因此,这里我们可以省略所有的分母以简化矩阵表示,而不会影响结果的正确性。这么做显然使我们丢失了误差的一部分比例信息,但却能带来巨大的性能提升,显著降低反向传播的计算复杂度,因此是值得的。
优化后的误差计算表达式为:
$$ e^{\prime} = \begin{pmatrix} w_{1,1} & w_{1,2} \\ w_{2,1} & w_{2,2} \end{pmatrix} \cdot \begin{pmatrix} e_1 \\ e_2 \end{pmatrix} = w^T \cdot e $$
现在的表达式简洁多了,这与前馈信号的计算形式基本一致。不同之处在于我们对原始的权重矩阵进行了转置。
梯度下降法更新权重
现在我们已经掌握了神经网络的信号前馈和误差反向传播的计算方法,距离实现实际的训练只差最后一步:依据误差指导权重的更新,也即最小化损失函数。我们将采用一个非常著名的权重更新方法,梯度下降法(Gradient Descent)。
梯度下降的原理同样简单易懂,由于误差的本质是一个关于权重的函数,为了让误差尽可能小,我们在每一轮训练过程中将权重向误差梯度的负方向移动一小段距离。反映在函数图像上,即自变量的改变量与函数的导数呈负相关关系。
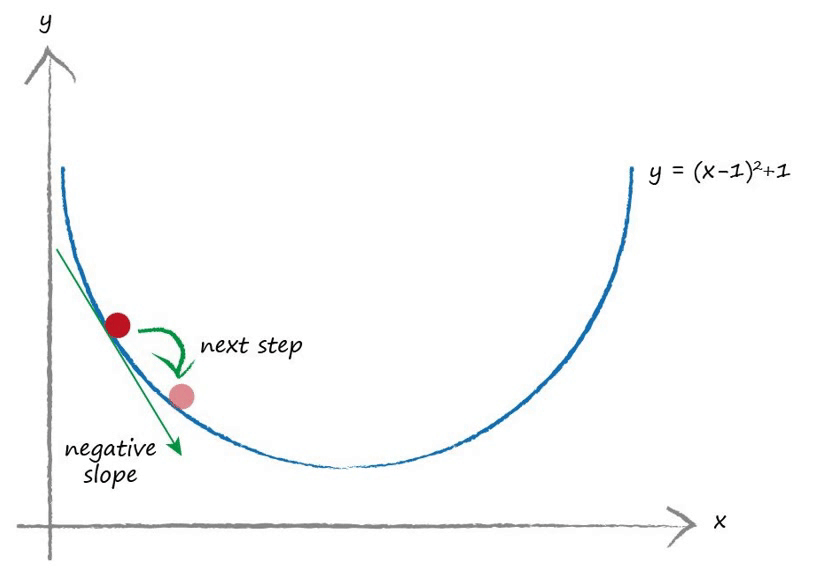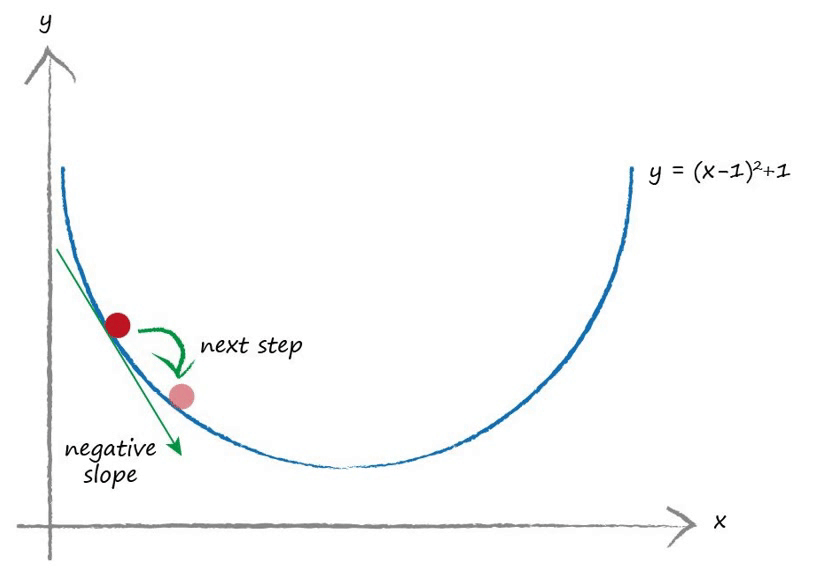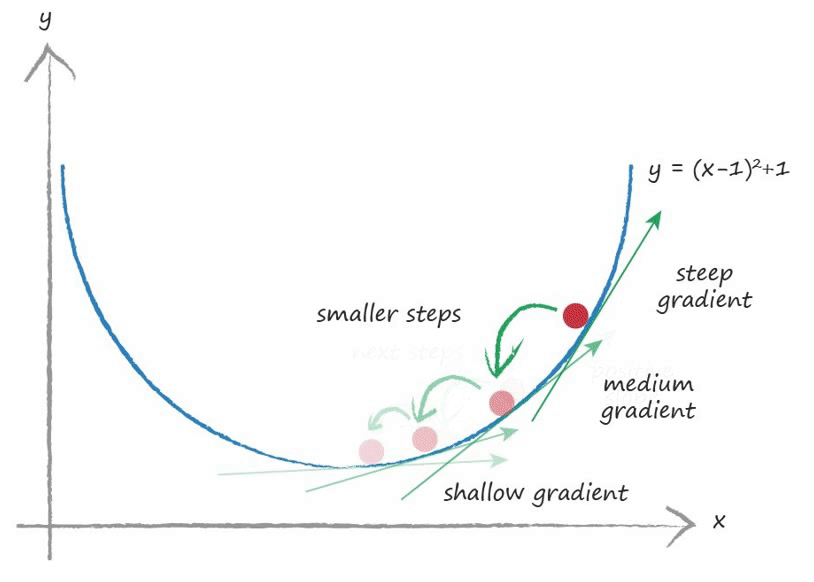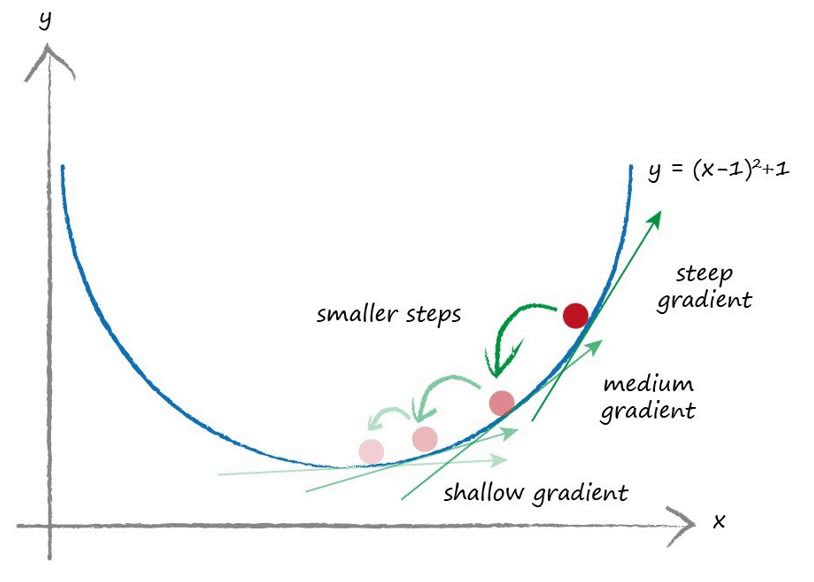
因此,我们只需要将损失函数对各个权重变量求偏导数,将得到的结果取反作为权重的改变量即可。
具体的求导过程如下所示,需要注意的是其中包含了对sigmoid函数的求导,且计算过程中需要用到链式法则(Chain Rule)。
$$ \begin{align} \frac{\partial{E}}{\partial{w_{j,k}}} &= \frac{{(t_k – o_k)}^2}{\partial{w_{j,k}}} = \frac{{(t_k – o_k)}^2}{\partial{o_k}} \cdot \frac{\partial{o_k}}{\partial{w_{j,k}}} = -2(t_k – o_k) \cdot \frac{\partial{o_k}}{\partial{w_{j,k}}} \\ &= -2(t_k – o_k) \cdot \frac{\partial{sigmoid(\sum_j{w_{j,k} \cdot o_j})}}{\partial{w_{j,k}}} \\ &= -2(t_k – o_k) \cdot sigmoid(\sum_j{w_{j,k} \cdot o_j}) \left( 1 – sigmoid(\sum_j{w_{j,k} \cdot o_j}) \right) \cdot \frac{\partial{(\sum_j{w_{j,k} \cdot o_j})}}{\partial{w_{j,k}}} \\ &= -2(t_k – o_k) \cdot sigmoid(\sum_j{w_{j,k} \cdot o_j}) \left( 1 – sigmoid(\sum_j{w_{j,k} \cdot o_j}) \right) \cdot o_j \end{align} $$
以上便是损失函数关于各个权重的梯度值,最终的数学公式仍然看上去十分复杂,但我们仔细分析便不难发现,其中的sigmoid部分其实就是目标层的前馈信号的计算结果,最后的\(o_j\)实际上表示的是上一层的输入矩阵的转置,而平方损失函数在这个求导后的公式中不复存在,取而代之的是一维线性差值\((t_k – o_k)\),我们将这个新的损失形式记为\(E_k\)。因此,让我们以符号化的形式重写梯度公式。
$$ \frac{\partial{E}}{\partial{w_{j,k}}} = -E_k \cdot o_k (1 – o_k) \cdot o_j^T $$
在对这个最终结果取反以得到权重的改变量之前,让我们额外增加一个变量,学习率\(\alpha\)。其值介于\(0\)~\(1\)之间,用来控制实际改变量的大小。记得在最初的例子中,我们其实并不希望每次都将斜率调整至贴近数据点的位置,而仅改变一个较小的距离反而可以取得更加理想的结果。实际应用中,学习率既不能设置的过大也不能过小,前者可能使结果难以拟合至最优,而后者容易陷入所谓的“局部最优”当中。
$$ \Delta{w_{j,k}} = -\alpha \cdot \frac{\partial{E}}{\partial{w_{j,k}}} = -\alpha \cdot (-E_k \cdot o_k (1 – o_k) \cdot o_j^T) $$
输入、输出及初始权重
最后,让我们回过头来关注一下输入、预期输出和初始权重的设置。这一部分很容易被忽略,但实际上极其重要。毕竟一个良好的开端能极大的缩减训练过程的开销。并且一个细微的错误很可能导致整个神经网络学习能力的丧失。
观察sigmoid函数的图像可以发现,它将所有的输入映射到\(0\)~\(1\)的区间中,且对于较大的输入值极其不敏感。考虑到神经网络各个层之间的信号传递会互为输出和输入,一个比较合理的做法是令输入数据也分布在\(0\)~\(1\)的区间范围内,使神经网络对输入足够敏感。但要特别注意的是,我们实际上应避免输入为\(0\)或\(1\),因为那样会导致梯度公式的计算结果为\(0\),从而致使整个神经网络失去学习能力。
因此,我们为输入添加一个小小的偏移,例如\(0.01\)~\(0.99\)。
类似的,我们的预期输出也应介于\(0\)~\(1\)之间,因为这是神经网络可能的实际输出值,若将预期输出设置为该范围之外的值将变得毫无意义。甚至误导训练过程。而为了避免诱导产生极大或极小的权重,我们同样最好将其设为\(0.01\)~\(0.99\)。
而对于初始权重,其实我们可以不必对齐进行过多约束。但数学经验已经证明,使用介于\(\frac{-1}{\sqrt{n}}\)~\(\frac{1}{\sqrt{n}}\)(其中\(n\)为传入连接的数量)之间的符合正态分布的随机初始权重是一个合理的做法。其实这也很容易想象其合理性,当节点数量增加时,每个节点对输出造成的影响会减小,其对应的连接的强度也会相应减小。
然而非常重要的一点是,打破对称性(Break Symmetry),任何时候应避免将权重初始化为相同的常量,因为那样会令所有权重在训练过程中同步更新,导致其永远具有相同的值,失去了设置权重的意义。更糟糕的情况是,若将权重初始化为0,控制权重更新的梯度函数也将为0,从而使权重永久失去更新能力,这与设置输入信号为0或1是类似的。
NumPy代码示例
在实际应用人工神经网络的过程中,可以优化和调节的参数有很多,例如合理设置网络的层数和中间层的节点数,设置学习率,设置初始权重和训练迭代次数等等。
接下来,我们将使用Python的NumPy库从零搭建一个属于自己的3层人工神经网络,并完成对MNIST手写体数字数据集的识别和分类任务。
如果你仍感兴趣,请继续移步至《使用Numpy搭建基础人工神经网络》