感知机的对偶形式
感知机的对偶形式是对原始形式的一种优化计算的方法,它将原始形式的参数 \(w\) 表示为训练过程中每个点被选作误类点的次数 \(\alpha_i\) ,即 \(\alpha_i = n_i * \eta\),则对应的 \(w\) 可表示为:
$$w=\sum_{i=1}^N \alpha_i y_i x_i$$
因此,感知机的对偶形式可表示为:
$$f(x) = sign(\sum_{j=1}^N \alpha_j y_j x_j \cdot x + b)$$
从公式中可以发现,实际计算中 \(x_j * x\) 的值是不会变动的,因此可以提前计算出这些值以供取用,而不必在训练过程中每次都去计算它,从而大大加快了运行速度,这就是对偶形式优化之所在。计算所得的 \(Gram\) 矩阵是训练数据矩阵自身的内积,即 \(G = x \cdot x\)。
误分类点的判断方法:
$$y_i(\sum_{j=1}^N \alpha_j y_j x_j \cdot x_i + b) \le 0$$
初始参数取 \(\alpha\),\(b\) 均为 \(0\),参数更新方法:\(\alpha_i = \alpha_i + \eta\),\(b = b + \eta * y_i\)。
代码实现方面,数据处理部分和大致的框架和原始形式基本相同,只需在对应算法处进行改进。
1. 数据集的导入和预处理
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.datasets import load_iris
import time
iris = load_iris()
x = iris.data #数据
y = iris.target #标签
n_rate = 1 #学习率
#选取两类数据
x = x[0:100,[0,1]]
y = y[0:100]
size = y.shape[0] #数据总数
#标签设置为-1或1
for i in range(size):
if y[i] == 0:
y[i] = -1
2. 准备工作
在训练之前计算好 \(Gram\) 矩阵并初始化参数,同样将参数初始化为 \(0\)。
#计算GRAM矩阵 G = x @ x.T #初始化参数 a,b = np.zeros(size),0 epochs = 0 #记录迭代次数
3. 训练
类似之前的,这里只是改动了误分类点的判断方法和参数更新方法。另外,在训练结束之后需要由训练出的 \(\alpha\) 根据公式计算出对应的 \(w\) 以便进行最后的验证。
#开始训练
while True:
epochs += 1
mistake_count = 0
mistake_list = []
for i in range(size):
if y[i]*(np.sum(a*y*G[i])+b) <= 0: #判断误分类点
mistake_count += 1
mistake_list.append(i)
if mistake_count == 0:
break
rand_i = random.choice(mistake_list) #随机选取误分类点
a[rand_i] += n_rate
b += n_rate * y[rand_i]
#计算参数w
a = a[:,np.newaxis] #增加一个维度,转换为列矩阵
y = y[:,np.newaxis] #增加一个维度,转换为列矩阵
w = np.sum(a*y*x,axis=0)
4. 绘图
print('迭代次数:',epochs)
print('w=',w,',b=',b)
x_plot = np.linspace(4,7,10)
y_plot = -(w[0]*x_plot+b) / w[1]
plt.plot(x_plot,y_plot)
plt.plot(x[:50,0],x[:50,1],'rx',label='0')
plt.plot(x[50:100,0],x[50:100,1],'bo',label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()
最终运行结果如下:
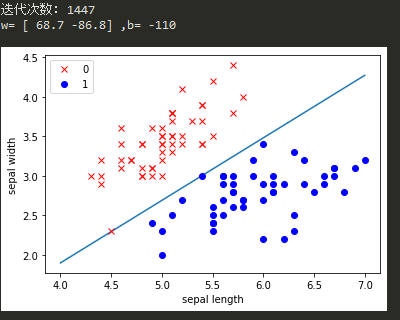
结果分析:
可以看到,最终的结果是和原始形式的结果基本一致的,无论是迭代次数还是参数值都基本并无二致,这是因为算法中仍然是通过每次发现并记录一个误分类点对应的参数来达成最终的结果,因此计算次数相同,而计算方法得到了优化,免去了每次训练都必须进行的矩阵运算而改为简单的数值运算。下面将着重对比二者的运行时间和效率。
原始形式与对偶形式的对比:
在代码中加入时间计算函数time.perf_counter()即可得到程序运行的时间,两种方法的时间开销如下:
原始形式:
时间开销: 0.7102019000000155 迭代次数: 1266 w=[ 62.3 -79.8] ,b= -97
对偶形式:
时间开销: 1.605608200000006 迭代次数: 1280 w=[ 63.7 -80.9] ,b= -101
可以看到,结果并不如预期的那样,反而对偶形式比原始形式慢了1秒左右的时间,推测原因有两点:1)计算的矩阵大小较小,所使用的鸢尾花数据仅仅是包含两个值的1*2的矩阵,因此对偶形式在加速矩阵运算上的优势显示的不明显,反而额外的循环求和过程加大了时间开销。如若处理复杂的高维数据则对偶形式的优势会明显的体现;2)数据数量较小,数据总数仅为100个,同样使对偶形式的优势无法体现。
感知机算法原理简单易于求解,但也存在一定的缺陷和局限性,首先它只能处理线性可分的二分类数据,而对多分类和异或问题无能为力,其次,感知机所得的解不唯一且计算过程的时间开销的大小根据随机选择的误分类点的不同有一些运气成分,但时间开销上限是确定的。